AI Agents and Document Processing: What's Actually Changing in 2026
AI agents are reshaping how businesses handle document extraction — but not in the way most articles suggest. Here is what is genuinely new, what is hype, and what it means for your team.

If you follow anything in the software industry right now, you have seen the term AI agents applied to almost everything. Document processing is no exception. Vendors are rebranding products, analysts are updating forecasts, and finance teams are being asked whether they need to rethink how they handle invoices and PDFs.
Most of the coverage either overpromises or stays too abstract to be useful. This article tries to do something different: explain what AI agents actually mean in the context of document extraction, what is genuinely shifting in 2026, and what a practical ops or finance team should actually do about it.
A Quick History of Document Extraction
To understand what is changing, it helps to understand what came before.
OCR (Optical Character Recognition) was the first major step. It solved the conversion problem: turning a scanned image into readable text. OCR does not understand structure or meaning. It reads left to right, top to bottom, and produces a wall of text. Useful for archiving, not useful for extracting specific fields reliably.
Template-based and rule-based parsers came next. These added structure by letting users define where to find data on a document — highlight an area, name the field, extract from that position. Accurate and fast for documents that never change layout. Fragile the moment a supplier updates their invoice template or a new vendor arrives with a different format.
AI-powered extraction changed the picture significantly. Pre-trained models — trained on millions of real invoices, receipts, and bank statements — learned to recognise document structure without being told where to look. You upload an invoice; the model knows what an invoice looks like and pulls vendor name, date, total, and line items without a template. This approach handles layout variation far better than rules-based tools.
GPT-powered parsers pushed flexibility further still. Instead of relying on a model pre-trained for a specific document type, you describe in plain language what you want to extract, and a large language model reads the document and finds it. Useful for non-standard documents, messy email content, or edge cases that pre-trained models do not handle well.
That is the landscape most teams are working in today. Now, where do AI agents fit?
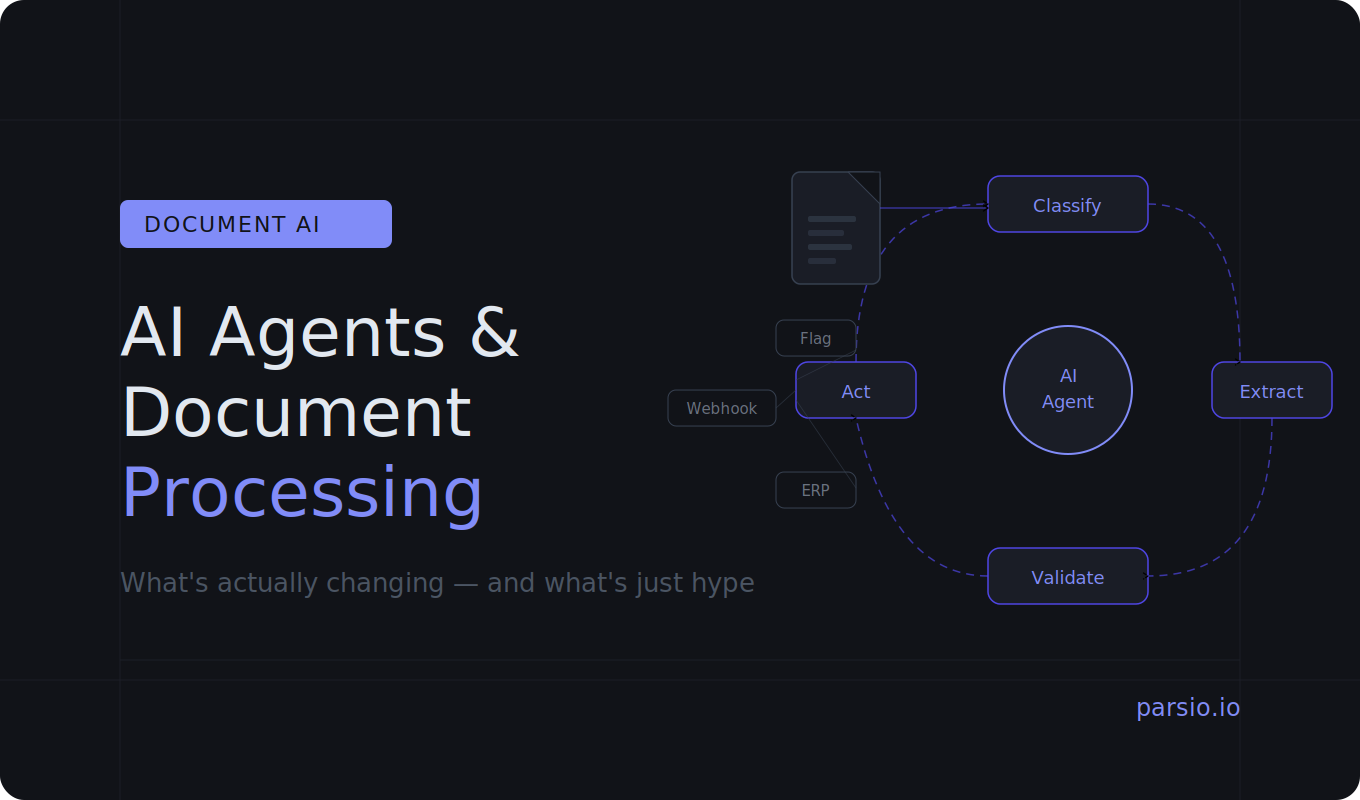
What Makes an AI Agent Different
An AI agent is not just an AI extractor. The distinction matters.
An extractor takes a document and returns structured data. It does one thing, in one step, with a defined input and a defined output.
An AI agent does more than that. It can:
- decide what type of document it is looking at before choosing an extraction approach
- run extraction, assess its own confidence, and try a different approach if the first attempt returns poor results
- cross-reference extracted values against other data — checking that line items sum to the total, or that an invoice number has not been seen before
- take follow-on actions: flagging discrepancies, routing documents to different workflows, triggering downstream tasks
- handle exceptions without immediately escalating to a human
In short, an agent does not just extract — it reasons, validates, and acts. The key difference is autonomy over multiple steps, not just accuracy on a single step.
In practice, a well-designed agentic document workflow for invoice processing might look like this:
- Document arrives by email or upload
- Agent classifies it: invoice, receipt, credit note, or other
- Agent extracts relevant fields using the appropriate method for that document type
- Agent validates extracted values against rules: do line items add up? Is this a duplicate?
- If validation passes, agent pushes data to the accounting system automatically
- If validation fails, agent flags the specific issue and routes it for human review
That last point is significant. One accounts payable team cited in industry research reported dropping their manual review rate from 40% to 4% after moving to an agentic approach — not because extraction became perfect, but because the system could resolve more edge cases on its own before escalating.
What Is Genuinely New in 2026
Several things have shifted enough in the past year to be worth noting.
Vision-language models have matured. Models that understand both the visual layout of a document and the meaning of its content are now practical to deploy. Earlier approaches treated OCR output as text and applied language models to it. Current approaches read the document as an image — understanding that a number in the bottom-right corner of a table means something different from a number in a header. This improves accuracy on complex layouts without requiring templates.
Multi-step reasoning has become cheaper. Running a document through multiple passes — extraction, validation, correction — was expensive and slow a year ago. Model efficiency improvements have made multi-step agentic pipelines more practical for the volume of documents most businesses actually process.
Exception handling has improved dramatically. Traditional document processing systems escalated to humans whenever confidence dropped below a threshold. Agentic systems try harder first. If field extraction is ambiguous, the agent can look for the same value elsewhere in the document, compare it to a known pattern, or ask a clarifying question before giving up. Escalation rates have dropped for teams that have deployed these systems.
The integration layer has caught up. Agentic processing is only useful if the extracted data can actually trigger something downstream. Tools that connect document output to CRMs, ERPs, accounting systems, and spreadsheets have improved significantly, making it easier to build end-to-end workflows without custom engineering.
Where Agentic Processing Adds Real Value
Agentic approaches genuinely outperform simpler extraction in specific situations:
- High document variety. If you receive documents from dozens of suppliers, each formatted differently, with no stable template, agentic systems handle variation better than anything that requires per-supplier configuration.
- Validation-heavy workflows. Accounts payable, procurement, and compliance processes where each extracted document needs to be checked against rules or other data before an action is taken. Agents can automate that checking step.
- Complex exception handling. Workflows where you currently have a human reviewing a large percentage of documents not because extraction is failing, but because the system cannot resolve the edge cases without human judgement.
- Downstream action chains. When the goal is not just to extract data but to trigger something — update a record, send a notification, match a purchase order, approve a payment — agentic architecture handles those chains more reliably than brittle integration scripts.
Where It Adds Complexity Without Value
Agentic processing is not the right answer for every document workflow. It is worth being clear about the cases where it adds overhead rather than benefit.
Stable, high-volume document types from known sources. If you receive the same invoice format from the same supplier every month, a template-based or pre-trained AI parser is faster, cheaper, and more predictable than an agentic pipeline. There is no variation to handle. The complexity of multi-step reasoning is not earning anything.
Short, simple workflows with no downstream action chains. If all you need is to extract a few fields from a PDF and get them into a spreadsheet, a direct AI extraction approach works fine. Adding agent architecture to a simple extraction task is like using a cargo ship to deliver a letter.
Low document volume. Agentic systems shine at scale. For a small business processing ten invoices a week, the setup cost and ongoing complexity of a full agentic pipeline is hard to justify. A tool that does good AI extraction with a clean export integration gets you 90% of the outcome with 10% of the effort.
Unpredictable or very long documents. Agents still struggle with very long, highly unstructured documents — long contracts, multi-hundred-page reports, documents where the same information might appear in multiple places with conflicting values. These cases require human judgement that agents cannot yet reliably replace.
What This Means for Your Team Today
The practical question for most operations and finance teams is not whether AI agents are real — they are — but whether adopting full agentic architecture now is the right move for their actual workflows.
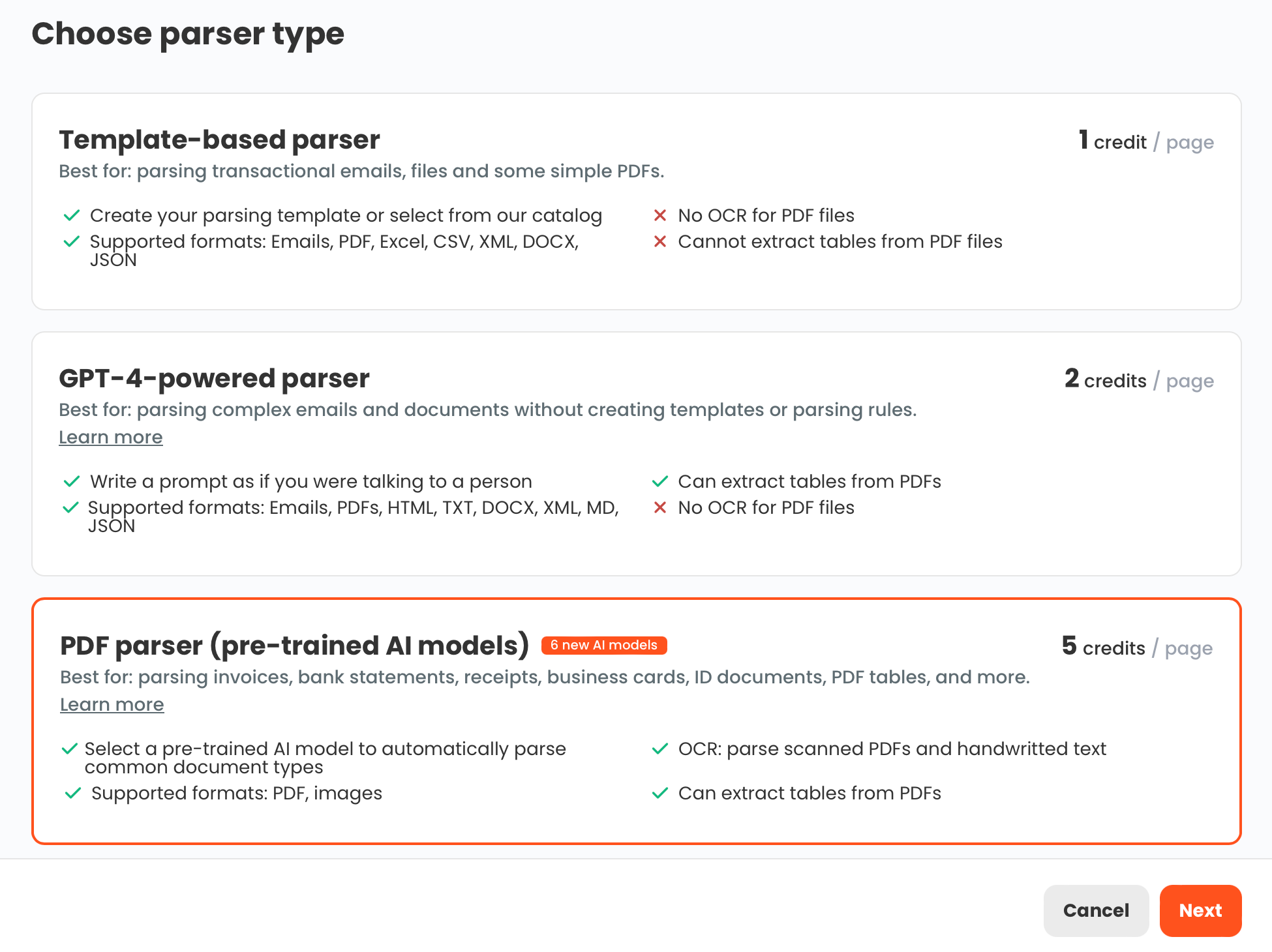
A useful framing: the core problem AI agents are solving — handling document variation without constant manual configuration — is also what multi-engine extraction tools have been solving, with different trade-offs.
A platform that lets you apply template-based extraction to stable document formats, AI pre-trained models to known business document types, and a GPT-powered approach to everything else is already giving you a large share of what agentic architecture delivers — with less complexity, faster setup, and more predictable costs. The judgment about which engine to use is yours rather than the system's, but for most SMB document workflows, that is a reasonable trade.
Full agentic architecture makes most sense when you have a document processing problem at a scale and complexity that exceeds what rule selection and good extraction can handle. For many teams, that threshold is higher than the current marketing suggests.
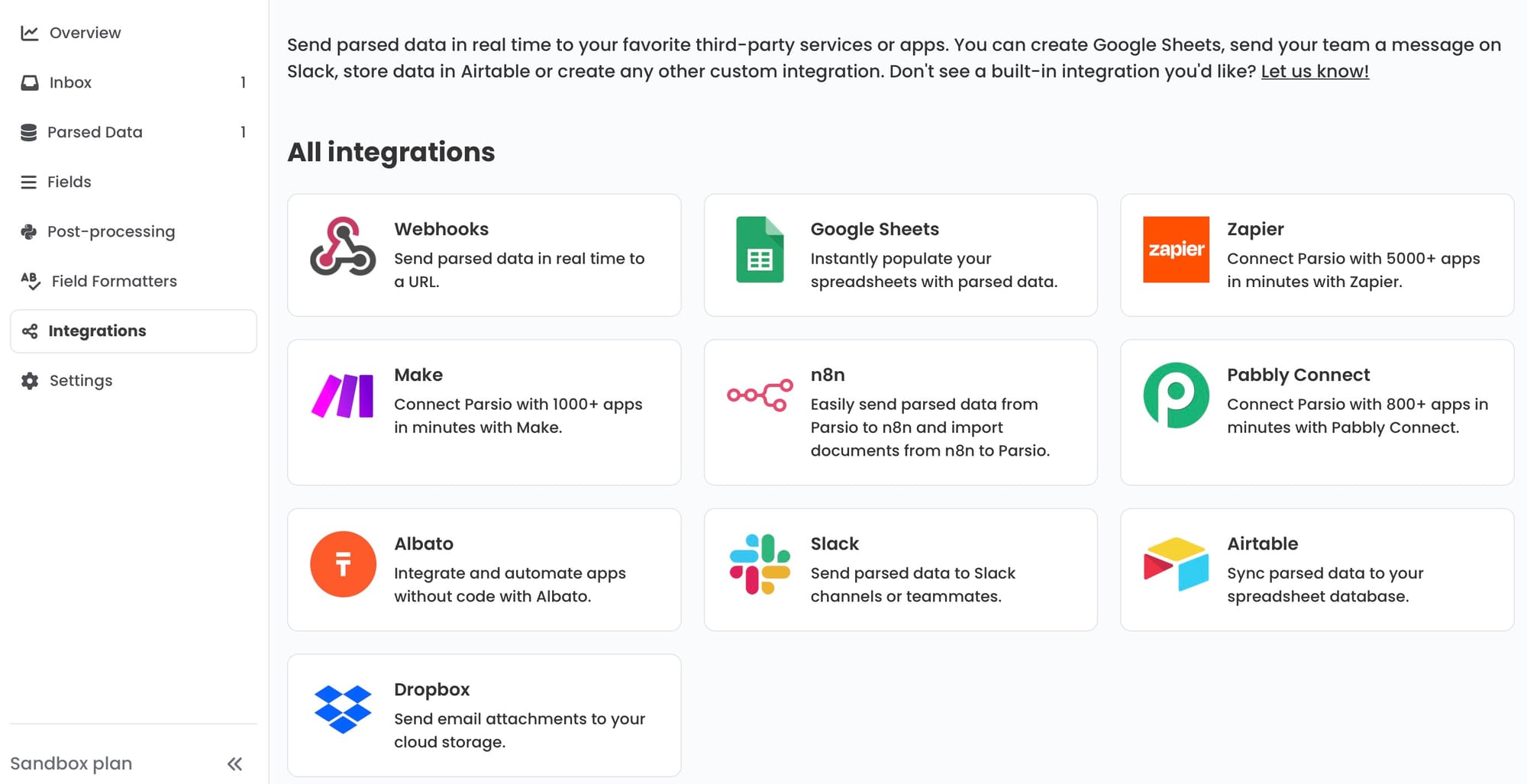
The integration layer is where many teams still leave value on the table. Even with excellent extraction, if the output sits in a CSV that someone downloads manually, the workflow is still largely manual. The real productivity gain — agentic or not — comes from connecting extracted data directly to the tools that use it: accounting software, CRMs, Google Sheets, or internal systems via webhook.
👉 For a detailed comparison of extraction approaches, see PDF Parsing Methods Compared: Rule-Based, Zonal OCR, AI, and LLM Approaches.
👉 If you are starting with document extraction, Guide to Document Data Extraction Using AI in 2026 covers the foundations.
👉 For email-specific workflows, see How to Automate Data Extraction from Emails in 2026.
FAQ
What is an AI agent in document processing?
An AI agent is a system that does more than extract data from a document — it reasons over the result, validates it against rules, handles exceptions, and triggers follow-on actions autonomously, without human intervention at each step. The key distinction is multi-step autonomous behaviour, not just accurate extraction.
How are AI agents different from AI OCR tools?
AI OCR extracts text or structured fields from documents. An AI agent goes further: it can classify documents, choose an extraction method, validate the result, resolve ambiguity, and trigger downstream actions — all without a fixed script. OCR is one input step in what an agent does.
Do I need an agentic system for invoice processing?
Not necessarily. For standard invoice formats from known suppliers, a pre-trained AI model extracts cleanly without agentic complexity. Agentic approaches add value when you deal with high document variety, complex validation rules, or downstream action chains that need to happen automatically. Start with the simplest approach that solves your problem reliably.
Is agentic document processing expensive?
It depends on implementation. Enterprise agentic platforms are priced for enterprise volume and come with significant setup costs. For smaller teams, using a multi-engine extraction tool with good integration options captures most of the practical benefit at a fraction of the cost and complexity.
What document types benefit most from agentic processing?
Documents with high layout variation across senders, complex validation requirements, or downstream actions that need to happen automatically benefit most. Simple, stable, high-volume document types — like order confirmations from a single system — are usually well served by simpler extraction approaches.
