Automating Document Classification: Everything You Need to Know
Explore the power of automating document classification for businesses. Discover how technologies like Machine Learning, Deep Learning, and GPT revolutionize document classification processes.


In today's data-driven world, businesses are inundated with vast amounts of documents ranging from invoices and contracts to emails and customer feedback. Managing this influx efficiently is paramount for productivity and decision-making. This is where document classification can help businesses. In this article, we will discuss everything you need to know about automating document classification.
What Is Document Classification?
Document classification refers to the process of categorizing documents into predefined classes or categories based on their content. This technology enables businesses to organize, manage, and extract insights from their data effectively.
Use Cases of Document Classification
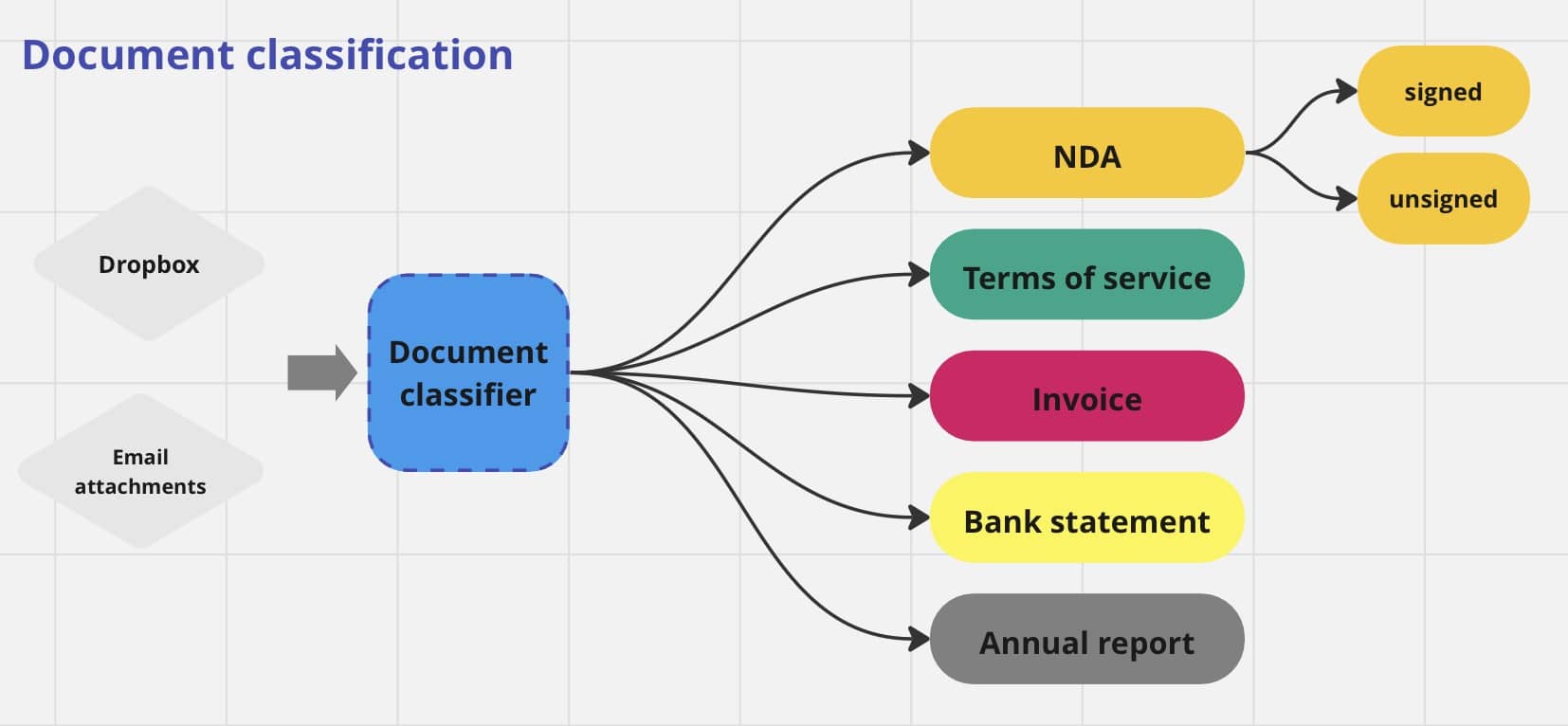
Invoice Management
Consider the scenario where a company receives numerous invoices daily, ranging from reimbursements to office expenses and payments for third-party software. Manually sorting these invoices into different categories is impractical and error-prone. However, with document classification, businesses automate this process, accurately categorizing invoices based on their content. This not only saves time but also ensures better organization and accessibility of financial records.
Email Filtering
Email overload is a common challenge for professionals, particularly those in managerial or administrative roles. Sorting through hundreds of emails daily to identify important messages can be overwhelming with all the clutter. Document classification algorithms enable businesses to automatically categorize emails based on their content, distinguishing between crucial communications, junk mail, and newsletters. This enables businesses to prioritize their responses and focus on tasks that demand immediate attention.
Legal Document Management
Law firms and legal departments deal with a vast array of documents, including contracts, court filings, briefs, and legal opinions. Efficiently managing and retrieving these documents is essential for maintaining compliance and providing timely legal assistance. Document classification systems can automatically categorize legal documents based on case type, jurisdiction, or legal issue, facilitating quicker retrieval and analysis when needed.
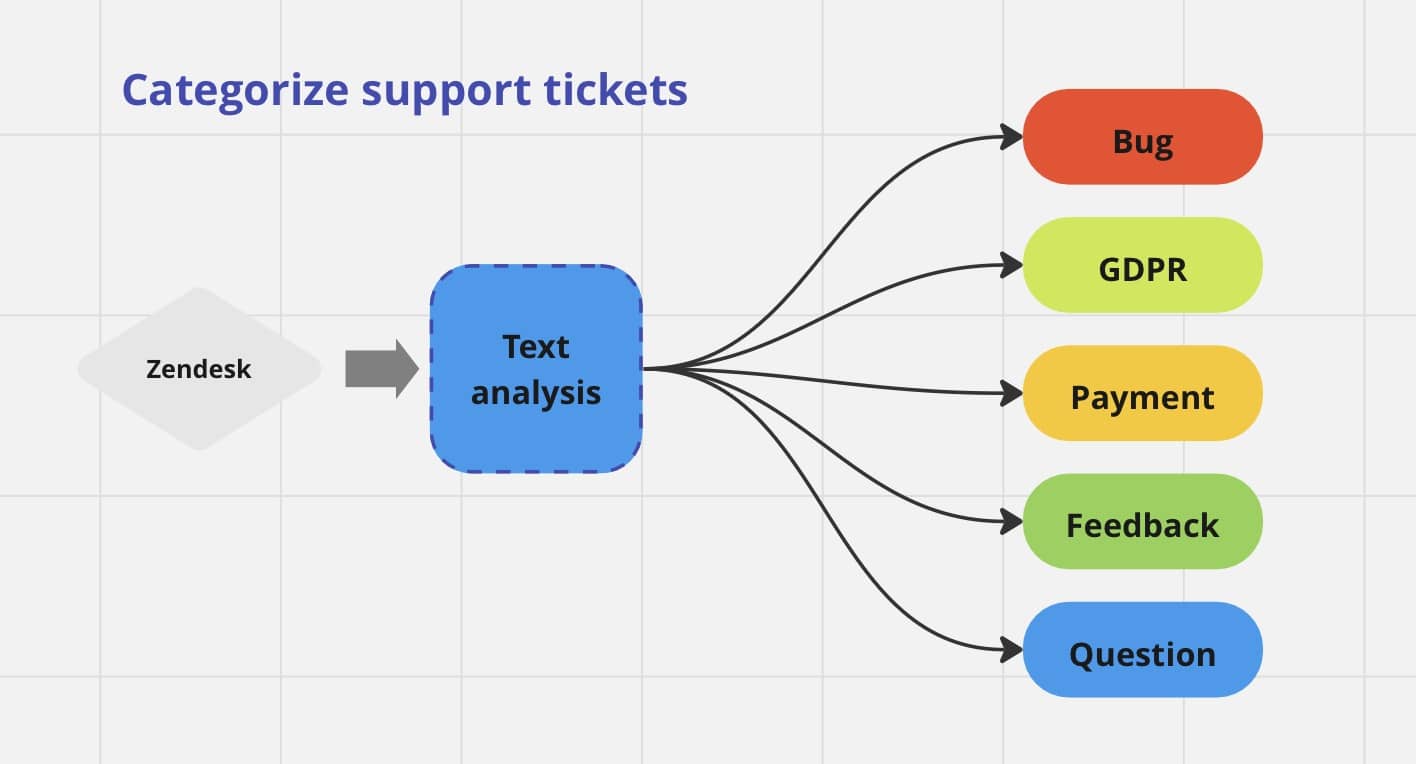
Customer Support Ticket Classification
In industries like e-commerce or telecommunications, involving high customer interaction, managing support tickets efficiently is crucial for maintaining customer satisfaction. Document classification algorithms can categorize support tickets based on the nature of the issue, enabling customer service teams to prioritize and address them accordingly. This streamlines the resolution process and enhances overall service quality.
Benefits
Increased Efficiency
Automation of document classification significantly enhances efficiency by minimizing the need for manual intervention. Instead of relying on human effort to sort through and categorize documents, automated systems can process large volumes of data rapidly. This accelerated processing speed translates to faster decision-making and improved overall workflow efficiency. Tasks that would otherwise consume valuable time and resources can be completed efficiently, allowing employees to focus on more strategic and high-value activities.
Improved Accuracy
Advanced algorithms and machine learning models used in automated document classification systems greatly enhance accuracy compared to manual classification methods. Human error, fatigue, and inconsistencies inherent in manual processes are mitigated, leading to higher levels of data integrity and reliability. Automated systems can analyze documents with precision, ensuring that they are assigned to the correct categories or classes based on their content. This accuracy is crucial for maintaining the integrity of data-driven decision-making processes within organizations.
Cost Savings
By streamlining document management processes, automated classification systems contribute to significant cost savings for businesses. The reduction in manual labor requirements translates to lower operational expenses associated with employee salaries, training, and potential errors. Moreover, the increased efficiency achieved through automation enables organizations to optimize resource allocation and maximize productivity. Over time, the cumulative cost savings derived from automated document classification can have a positive impact on the bottom line, improving profitability and competitiveness.
Scalability
Automated document classification systems are inherently scalable, capable of handling large volumes of documents without compromising performance. As businesses grow and accumulate more data, the scalability of automated systems becomes increasingly valuable. Whether dealing with thousands or millions of documents, these systems can adapt and scale to meet the organization's evolving needs. This scalability ensures that document management processes remain efficient and effective, regardless of the size or complexity of the dataset.
How Document Classification Works?
Document classification can be done manually or automatically. Manual classification involves humans interpreting text, understanding relationships between concepts, and categorizing documents accordingly. While this method offers control, it's costly and time-consuming. Automatic document classification, on the other hand, uses technology like machine learning to classify documents automatically. This approach is faster, scalable, and more objective. There are three main methods.
Supervised Method
Here, a classifier is trained on a set of documents that have already been manually tagged. The classifier learns from this tagged data and can predict categories for new documents. It can also provide a measure of confidence in its predictions. Users play a role by labeling a set of documents for the system to learn from.
Examples of technologies:
- Machine Learning Models: Examples include Support Vector Machines (SVM), Naive Bayes, and neural networks. Libraries like scikit-learn in Python provide implementations of these algorithms.
- Deep Learning Frameworks: TensorFlow and PyTorch are popular for building more complex models that require significant computational resources but can achieve high accuracy.
Unsupervised Method
Documents are grouped based on similarities in their words and phrases, without the need for manually labeled training data. In other words, unsupervised learning finds patterns in the data without needing labeled examples. It's particularly useful for discovering natural groupings or clusters in the data.
Examples of technologies:
- Clustering Algorithms: K-means and hierarchical clustering are common methods for grouping similar documents. Tools like the Natural Language Toolkit (NLTK) and scikit-learn in Python support these techniques.
- Dimensionality Reduction: Techniques like t-SNE or PCA are often used to visualize document clusters by reducing the feature space to two or three dimensions.
GPT / LLM Method
This innovative approach leverages the capabilities of Large Language Models (LLMs) like GPT (Generative Pre-trained Transformer) for document classification. Unlike traditional methods that rely on statistical, mathematical, or rule-based algorithms, GPT and similar models understand and process natural language at a level that mimics human comprehension. This allows for more nuanced and context-aware classification of documents.
How it Works:
- Pre-training on Diverse Data: GPT models are pre-trained on a vast corpus of text, enabling them to grasp a wide range of topics, styles, and contexts. This broad knowledge base allows them to effectively categorize documents even in complex or niche domains.
- Fine-tuning for Specific Tasks: Although pre-trained on general data, these models can be fine-tuned with a smaller, task-specific dataset. This process adapts the model to the particular nuances of your document set, enhancing its classification accuracy.
Examples of technologies:
- OpenAI's GPT Series: Including GPT-3 and the upcoming versions, which are at the forefront of LLM technology, offering powerful natural language processing capabilities.
- Hugging Face's Transformers Library: Provides access to thousands of pre-trained models, including GPT and other transformer-based models, which can be used for a variety of NLP tasks including document classification.
Final Thoughts
Automating how companies sort and make use of their data is changing with tools like Parsio. Parsio offers a simple way to classify documents, fitting the needs of various business sizes. It uses advanced AI, including GPT technology, to make document classification easier and more efficient, saving time and resources. This shows Parsio's focus on using the latest AI to make document classification better and easier for businesses.