How to Extract Data from PDFs Using ChatGPT?

The advent of AI and machine learning has considerably transformed the way we manage, process, and interact with data. In the sphere of document management, one common format that stands out is the Portable Document Format (PDF). With the increasing digitalization of information, the ability to effectively extract and interact with data within PDFs has become vital. That's where AI models like ChatGPT, developed by OpenAI, come into play. They not only provide interactive and intuitive ways to handle data but also bring in an element of automation and intelligence, making PDF processing easier and more efficient.
What are LLMs?
When it comes to creating artificially intelligent (AI) text, large language models (LLMs) are among the most promising. These models are built to analyze text and generate new text by figuring out what comes next in a sentence based on what has already been said. They learn from a wide variety of online content, so their finished products might cover everything from question answering and article summarization to creative writing and poetry.
LLMs are extremely flexible and have numerous potential uses. Email composing, coding, content creation, question answering, topic teaching, language translation, and many other tasks are only the tip of the iceberg of what they can do for you. They offer an innovative method of data extraction and administration, and can also be used to process and extract information from documents in formats like PDFs.
What's GPT-4 and ChatGPT?
Among the LLMs, ChatGPT is certainly the best-known name that has stunned the world right after its release in late 2022. Recently, we have seen a major upgrade with the official launching of GPT-4, which stands out due to its advanced text generation capabilities. While both GPT-4 and ChatGPT were developed by the same research company, OpenAI, there is a key difference that you need to understand.
GPT-4, the fourth iteration of the Generative Pre-trained Transformer series, is an extremely large-scale language model which employs machine learning to generate writing that sounds human-like from the data you feed it. ChatGPT is a specialized chatbot that uses GPT's language model to interact with humans in a natural and conversational way. In simple words, if ChatGPT is the car, then GPT is the engine that powers it. GPT-4, being the newer and more powerful version, is trained to perform better than its older variants.
ChatGPT is specifically fine-tuned for conversations. Trained on a diverse range of internet text, ChatGPT understands context and can answer questions, write essays, summarize text, and even generate creative content like poems or stories. With its impressive capabilities, it has wide-ranging applications, including, but not limited to, content creation, customer support, coding help, and data extraction, the last of which is particularly relevant for our discussion on PDF processing.
Why use ChatGPT for PDF data extraction?
Automating the extraction of data from PDFs can be a game changer, significantly reducing manual labor and time, and increasing the accuracy of data extraction. Here, ChatGPT comes into the picture with its advanced language understanding capabilities.

Automated Process: ChatGPT can process large volumes of text data and extract relevant information, eliminating the need for manual intervention.
Understanding Context: Unlike rule-based systems, ChatGPT understands the context of the data, ensuring more accurate extractions.
Versatility: It can work with a wide variety of document types and structures, not limited to a specific template.
Scalability: As an AI model, ChatGPT can scale up or down based on the volume of documents to be processed.
Examples of Queries and Results
Consider a set of financial reports in PDF format. You can ask ChatGPT to "Find the total revenue for Company X in 2022," and it would scan through the documents, locate the necessary data, and provide you with an accurate answer.
Similarly, for a collection of academic articles, a query like "Find all references to quantum entanglement in these articles" would prompt ChatGPT to sift through the PDFs and compile a list of all such references.
How Can You Make This Work Using Zapier?
To use ChatGPT for PDF data extraction, you first need to convert your PDF files into a text-based format. Once your data is in text form, you can use an automation platform like Zapier to integrate with ChatGPT and forward the converted text. This way, whenever a PDF is converted to text, the data is automatically sent to ChatGPT for processing.
Here's a step-by-step example:
- Upload a PDF file to your Dropbox folder or forward your PDF document as an email attachment to Zapier.
- Convert the PDF to plain text (you should use a third-party service for this).
- Send the raw text along with your query (e.g., "Find the total revenue for Company X in 2022") to ChatGPT.
- ChatGPT will analyze the text and provide you the structured data in response, which you can then export to Google Sheets or any other platform.
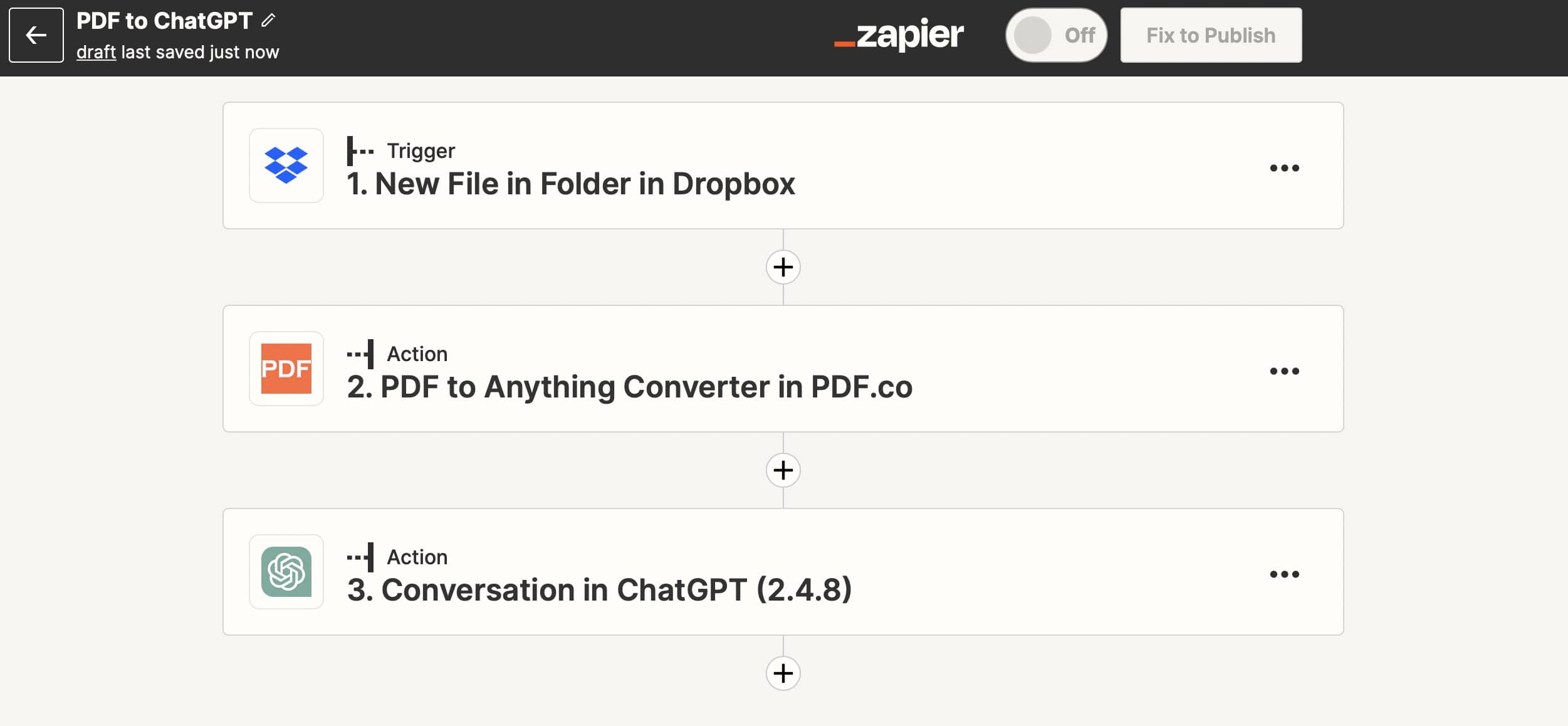
This automated pipeline can be customized according to your needs and can process multiple PDFs simultaneously, thereby saving time and resources.
A Better Solution: Using the New Parsio GPT-Powered Parser
We are thrilled to announce the launch of our new GPT-powered parser. You can now use natural language processing to extract structured data from emails, PDFs, HTML, TXT, DOCX, XML, MD, and JSON files.
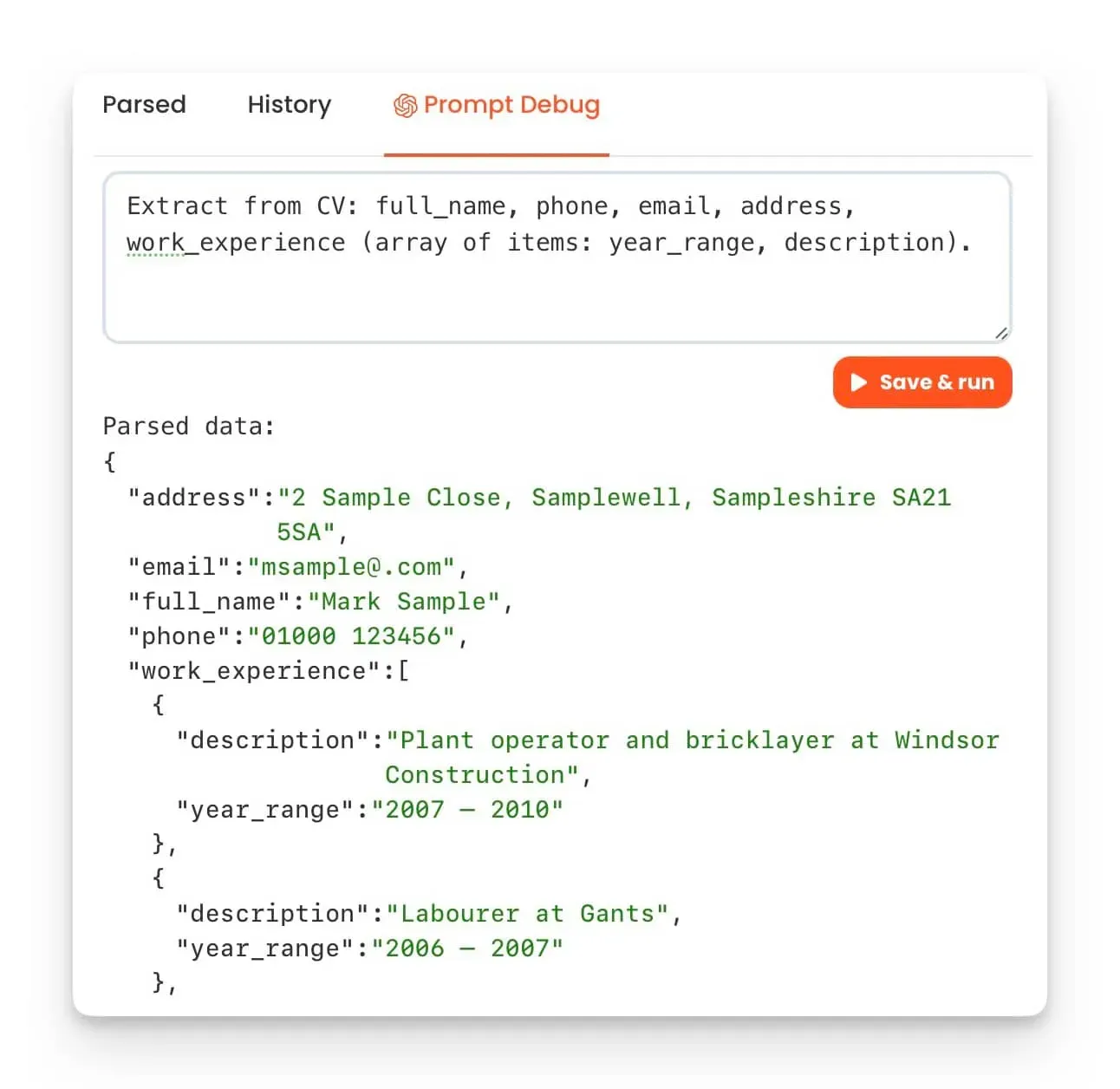
You can now parse unstructured documents such as CVs, recipes, product descriptions, and much more. This was not possible to achieve using traditional methods alone, including AI models.
Here's how it works:
- Import. Easily bring your emails and files into Parsio by forwarding them, uploading manually, or using our API for seamless integration.
- Write a prompt. Describe the desired data extraction as if you were conversing with a person. No complex parsing templates or rules needed.
- Export. Instantly send the parsed structured data to Google Sheets, webhooks, or any preferred platform.
Limitations & Drawbacks of PDF Parsing with ChatGPT
Despite its impressive capabilities, ChatGPT does come with its limitations when parsing PDF files.
Data Sharing with OpenAI: When you use ChatGPT, the data you process is shared with OpenAI. This could potentially raise privacy and confidentiality issues, especially when dealing with sensitive documents. However, it’s important to note that data submitted via API is not used to train or improve AI models according to OpenAI's API data usage policies.
Require Human Supervision: While ChatGPT is able to process PDF files, the text extraction with this tool is not always 100% accurate. You can find errors in the extraction of data, which means it is still far from complete automation and needs human intervention for supervision.
Cannot Process Complex Formatting: ChatGPT is a text-based model and cannot interpret or extract information from complex tables, diagrams, or other non-text elements in a PDF. If your PDFs contain critical information within such elements, you might need additional tools for recognition and analysis.
For instance, if you have a PDF with a lot of infographics, ChatGPT won't be able to interpret the data within these non-text elements. Similarly, if you're dealing with confidential financial reports, you might want to consider the data privacy implications. Considering its limitations, you might need to look for alternative tools that can extract text from PDF files with more precision and accuracy.
Parsio provides powerful AI-driven solutions to automate your data extraction. We utilize pre-trained AI models to parse common document types, including invoices, receipts, business cards, general documents, PDF tables, and more.
Final Thoughts
In a world that's increasingly data-driven, tools like ChatGPT offer innovative solutions for tasks like PDF data extraction. While it isn't without its limitations, its ability to automate and scale the process, understand context, and work with a variety of document types makes it a potent tool in the realm of document processing.
As technology continues to evolve, we can only expect these LLM models to become more sophisticated, further streamlining the process of data extraction and management.
If you’re looking for a reliable solution to process PDFs, then you can switch to an efficient document parser like Parsio to streamline your business workflow. Overcoming ChatGPT’s imperfections, it offers AI-powered OCR technology that can extract even complex or unstructured data effortlessly from any PDF document in a matter of seconds.