PDF Parsing Methods Compared: Rule-Based, Zonal OCR, AI, and LLM Approaches
Compare PDF parsing methods: rule-based, Zonal OCR, AI with pre-trained models, and LLM-powered extraction. Learn their pros, cons, and best uses.


Introduction
Parsing data from PDF files can be tricky. Some documents follow a strict format. Others change often. Some are scanned images. Others are digital and structured.
To deal with this, there are different parsing methods. Each one works best in different situations. In this article, we compare four main methods:
- Rule-based parsing
- Zonal OCR
- AI-powered parsing with pre-trained models
- LLM-powered parsing
Let’s see how they work, where they shine, and what to watch out for.
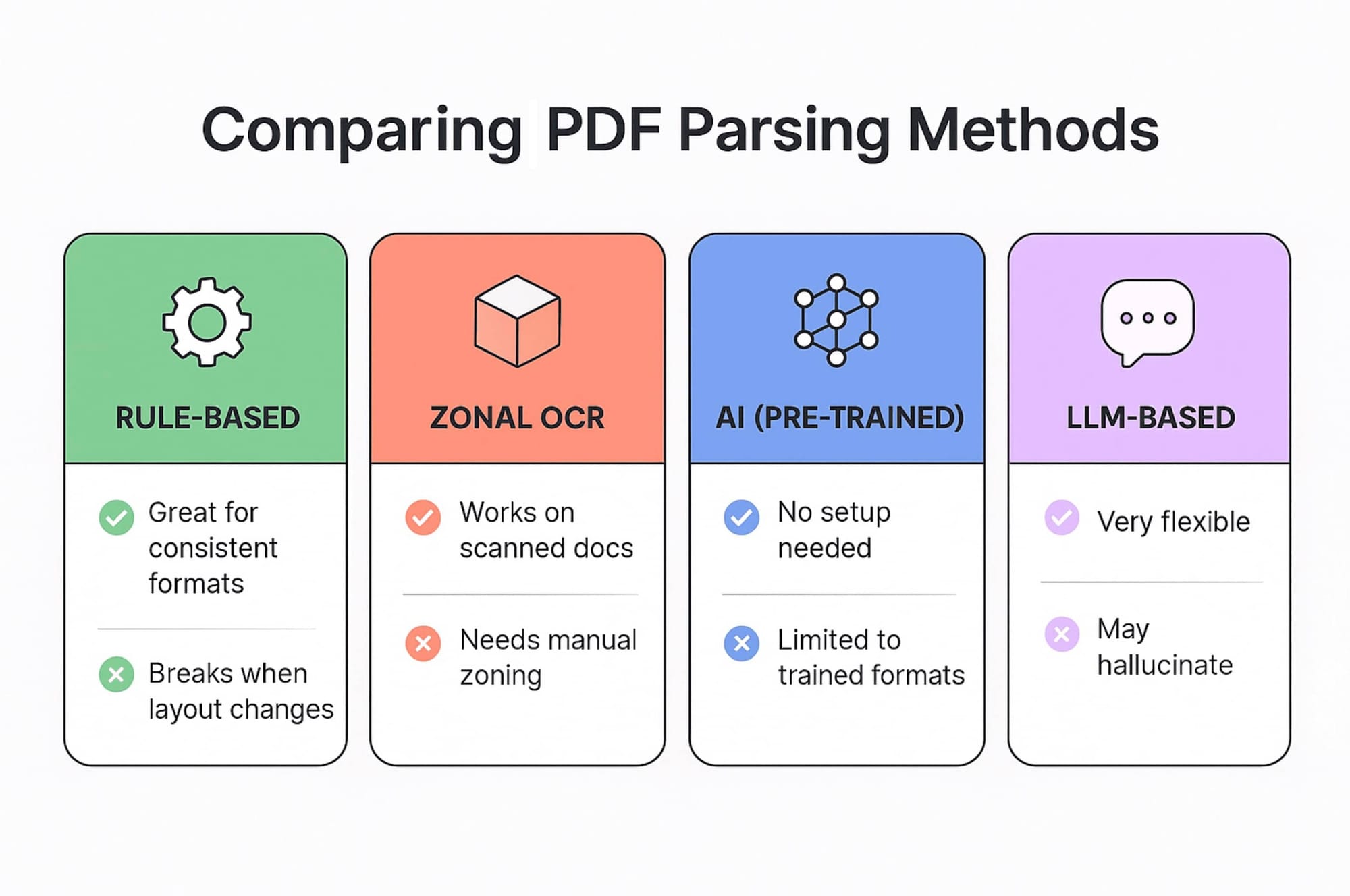
Rule-Based Parsing
How it works
Rule-based parsers use logic to find and extract data. You can create rules like:
- Find the word after “Order Number:”
- Get the line after "Invoice Date"
- Extract the number between two keywords
These rules rely on text patterns, keywords, or anchors.
Pros
- Simple to set up for basic use cases
- Works well for repetitive documents
- Transparent and easy to debug
Cons
- Breaks easily if wording or layout changes
- Can’t understand context or meaning
- Requires constant updates if formats change
When to use it
Great for parsing emails, order confirmations, or other structured texts. See our post on email data extraction and real estate email parsing.

Zonal OCR
How it works
Zonal OCR divides a scanned PDF or image into zones. Each zone extracts a specific piece of information based on coordinates. It’s useful when the layout is always the same.
Learn more in our Zonal OCR guide.
Pros
- Works on scanned and image-based documents
- Predictable output
- Doesn’t hallucinate like AI
Cons
- Manual to set up
- Doesn’t handle layout changes
- Sensitive to scan quality
When to use it
Use Zonal OCR for receipts, printed forms, or delivery notes. Check out automated receipt parsing.
AI-Powered Parsing with Pre-Trained Models
How it works
These models are trained on large collections of documents. They learn to recognize fields like invoice date, total amount, and vendor name.
You just upload a document. The AI finds the data.
Pros
- No setup needed for supported formats
- Handles layout changes
- Works for many common doc types
Cons
- Limited to the types it was trained on
- Can’t be easily customized for niche formats
- Not perfect for out-of-scope documents
When to use it
Best for invoices, bank statements, or purchase orders. See our top picks for bank statement extraction tools and invoice parsing with OCR.
LLM-Powered Parsing
How it works
LLM (Large Language Model) parsing uses models like GPT to read and understand documents. You define the fields you want, and the model extracts them based on meaning, not just structure.
Explore model comparisons in Extracting Data From PDFs Using AI.
Pros
- Extremely flexible
- No training needed
- Handles new and irregular document types
Cons
- May extract wrong or made-up values
- Harder to scale for large volumes
- Needs clear instructions to reduce errors
When to use it
Perfect for complex or unstructured docs. Examples: contracts, resumes, job offers, NDAs. See our article on legal document parsing.
Comparison Table
| Method | Pros | Cons | Best For |
|---|---|---|---|
| Rule-Based | Simple, transparent, editable | Breaks on format change, no understanding | Emails, fixed phrases |
| Zonal OCR | Good for scanned images, reliable | Needs manual setup, sensitive to layout | Receipts, delivery slips |
| AI (Pre-Trained) | No config, works on many formats | Limited to trained formats | Invoices, statements, common forms |
| LLM | Flexible, field-driven, no training | May hallucinate, slower, not always accurate | Contracts, custom documents |
Choosing the Right Parser
Here’s a quick guide:
- Use rule-based for simple, recurring patterns.
- Choose Zonal OCR for scanned layouts that never change.
- Go with AI models for typical business docs.
- Try LLMs for flexible, hard-to-parse files.
Sometimes combining methods works best. For example, use AI first, then fall back to LLMs for odd layouts.
Learn more about how AI transforms data extraction and scanned document parsing.
Conclusion
Every parsing method has its place. Rule-based is simple. Zonal OCR is reliable. Pre-trained AI is fast. LLMs are flexible.
At Parsio, you don’t have to choose just one. We support all of them. That way, you can build the parsing workflow that fits your documents.
Try Parsio for free and see what works for you.
