5 Effective Techniques for Extracting Information from PDF Documents
Discover the essentials of extracting information from PDF documents in our concise guide. We cover 5 key techniques: Template-based parsing, Zonal OCR, Pre-trained AI models, Training your own AI model, and GPT Parsing. We highlight their use cases, advantages, and disadvantages.


PDFs have emerged as a common format to share information. From businesses to academia and government offices, all make use of PDFs. However, the structured data within PDFs often remain locked away, inaccessible to automated processes without specialized extraction techniques.
In this article, we will explore 4 methods for extracting data from PDFs, delving into their respective use cases, advantages, and disadvantages.
1. Template-Based Parsing
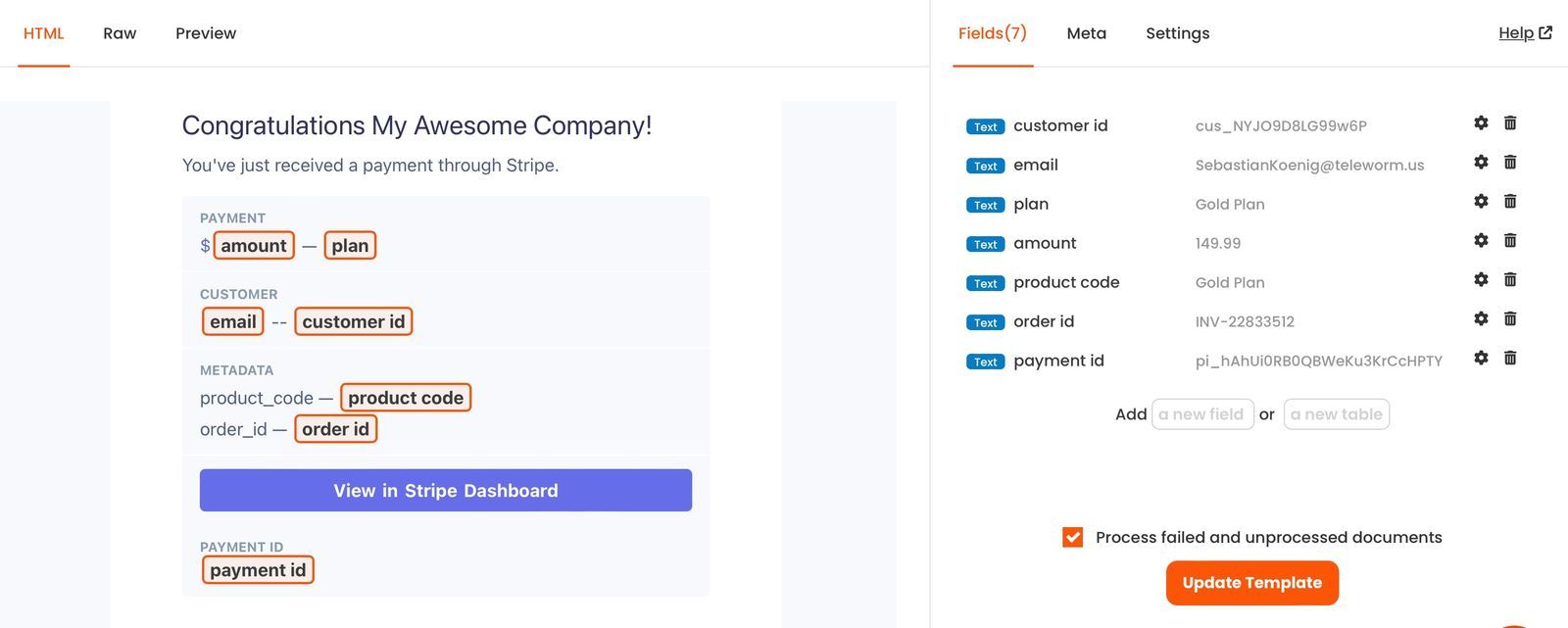
Template-based parsing techniques include analyzing the structure and format of the PDF document to pull out data. Rather than relying entirely on algorithms to understand the context, this method considers the layout and styling used within the PDF. By creating predefined templates that resemble the expected patterns within the document, extraction tools can accurately identify and capture relevant data.
Use Cases
The template-based parsing technique is best suited for extracting structured data from standardized forms, reports, and invoices available in PDFs. The method is also useful for extracting information from transactional emails.
Advantages
The major advantage of template-based techniques is their ability to handle documents with consistent formatting. This method leverages hard-coded rules that are tailored to the style of the document, thus offering higher accuracy in data extraction. Furthermore, template-based approaches are simple to implement and can be customized easily to suit different types of documents. This method is also suitable for batch processing.
Disadvantages
Template-based techniques may struggle with documents that have non-standard formatting. In such instances, maintaining and updating the templates can become time-consuming, as it might need constant adjustment to accommodate changes in document styles. Furthermore, the template-based parsing technique cannot reliably extract tables from the PDF files.
2. Zonal OCR
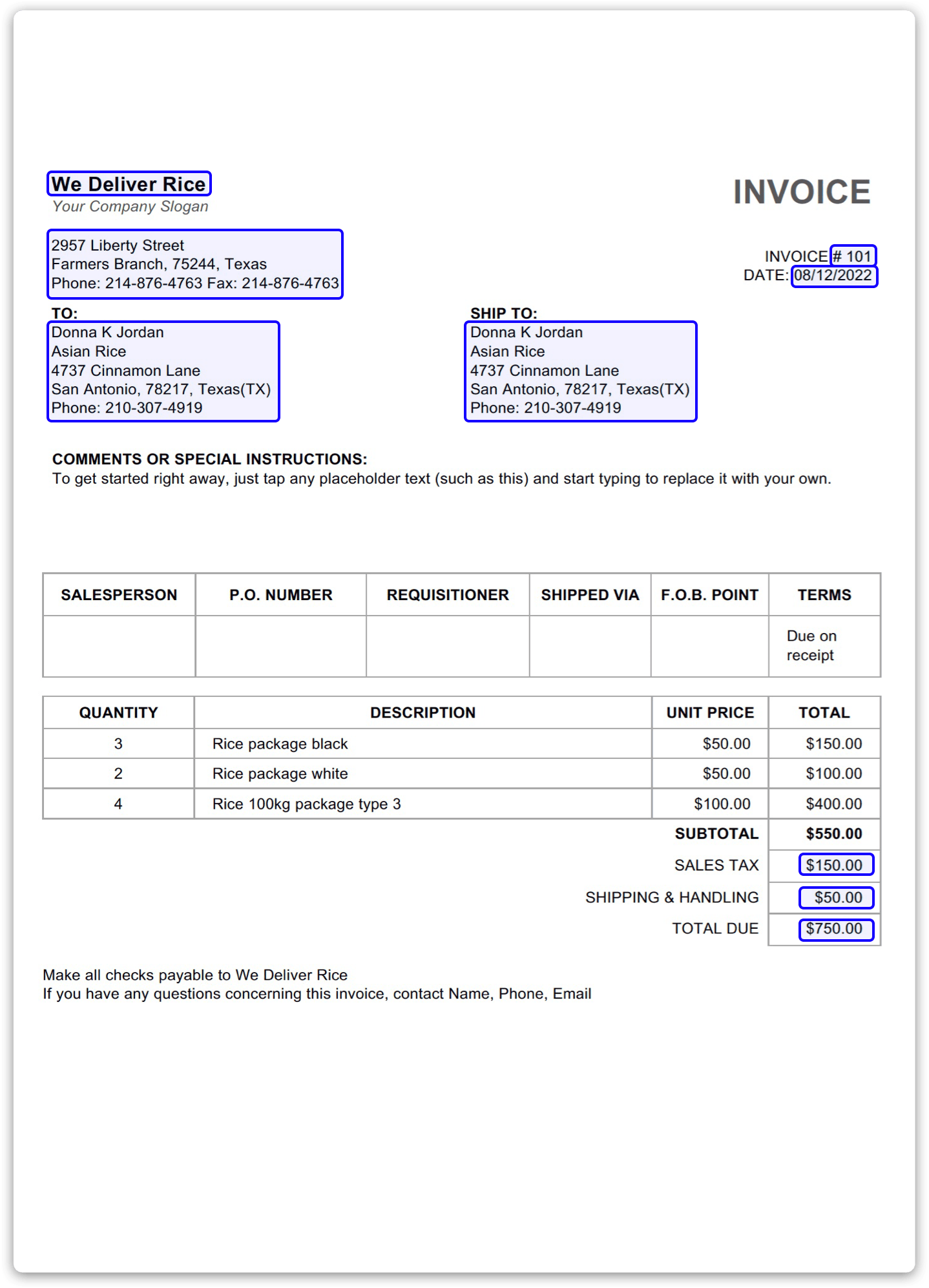
Zonal Optical Character Recognition (OCR) combines OCR technology with predefined zones or regions to extract data from specific areas of PDF. By defining zones, such as fields in a form or sections in a report, OCR accuracy and efficiency are enhanced, thus leading to improved data extraction results.
Use Cases
Zonal OCR is commonly used in document processing applications where structured data needs to be extracted from standardized documents. This method is effective for extracting data from predefined fields within forms, such as name, address, date, and other structured information. Zonal OCR can assist businesses in pulling out data from regulatory documents or compliance forms to ensure adherence to industry regulations.
Advantages
Zonal OCR streamlines the extraction process by focusing only on relevant areas of a document. This reduces the need for human intervention and speeds up data extraction. Zonal OCR offers flexibility in defining extraction zones and adapting to various document layouts, thus making it suitable for processing a range of documents, including PDFs.
Disadvantages
Setting up zonal OCR may require initial configuration and training to define extraction zones and optimize OCR settings for specific document types. Zonal OCR might find it difficult to extract data from documents that deviate from the expected layout, leading to inaccuracies in data extraction.
3. Pre-Trained AI Models
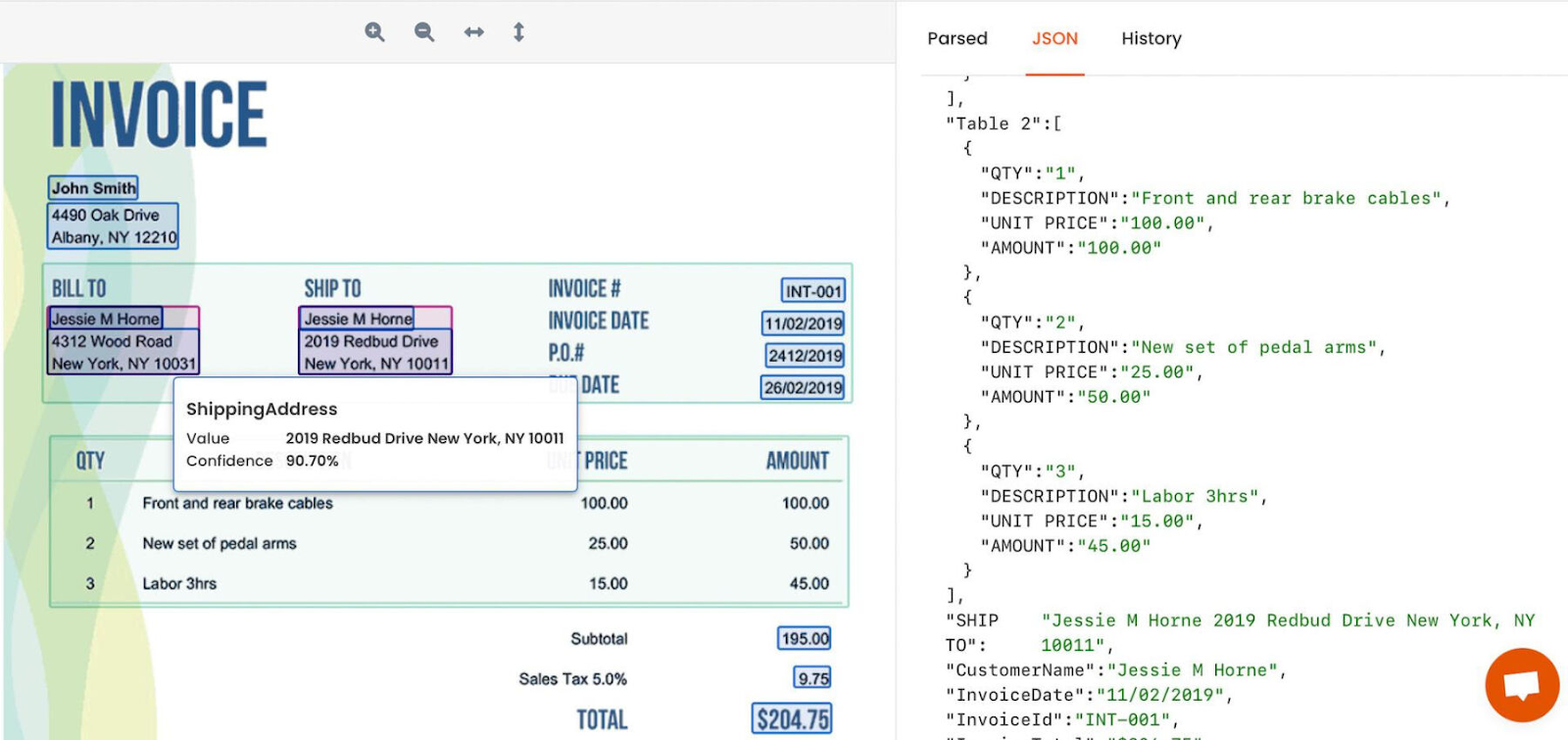
A pre-trained AI model is a powerful tool trained on vast amounts of data, such as invoices or other documents. This model is already equipped with the knowledge and understanding of various layouts and content structures commonly found in these documents. With minimal setup requirements, it can effortlessly extract structured data from PDFs, enabling automation of tasks like invoice processing.
Use Cases
Pre-trained AI models are best suited for extracting data from invoices, receipts, business cards, ID documents, PDF tables, and other general documents. One can also use pre-trained AI models for extracting data from standardized forms and contracts. These models can summarize the content of lengthy PDF documents by extracting key sentences or paragraphs, thus helping in document understanding.
Advantages
Pre-trained AI models are user-friendly as they do not need any initial setup or configuration. They are also good at handling PDFs with different layouts, like invoices coming from different vendors. It means that pre-trained AI models can easily extract data from all kinds of documents, making things easier for businesses.
Disadvantages
One of the major disadvantages is that pre-trained AI models are limited to the types of documents they have been trained on, like invoices. This means they can only handle those specific document types, and you can not really tell them exactly what information to extract. As a result, they might miss some important data fields during extraction.
Another disadvantage is their inability to verify the accuracy of the extracted information from the PDF. At times, the extracted text may contain errors or include unrelated information from different sections.
4. Train Your own AI Model
In addition to having pre-trained AI models, one can also develop their own custom models to extract data from PDF files. The model is trained using machine learning algorithms, adjusting parameters and fine-tuning the model until it delivers satisfactory performance by extracting information accurately.
Use Cases
Custom AI models can also be tailored to specific document types within various industries, thus offering accurate extraction capabilities. For instance, a business specializing in financial analysis might have unique report formats or templates that are used consistently across the organization. By training an AI model specifically on these financial report documents, it can learn to accurately extract relevant data such as numerical figures, tables, and textual information.
Advantages
Custom AI models are tailored to specific use cases and datasets. As a result, they often provide higher accuracy and reliability in extracting data from PDF documents. Furthermore, custom models can be optimized to handle unique document layouts or formats.
Disadvantages
The major challenge with a custom AI model is the need for significant amounts of labeled training data, which can be time-consuming as well as expensive. Moreover, the process of training and fine-tuning custom models requires expertise in machine learning and data science.
5. GPT Parsing
GPT parsing includes the use of the GPT model to understand and extract information from PDF documents. While primarily designed for natural language understanding tasks, GPT can be adapted for PDF data extraction by processing textual content and identifying relevant information.
Use Cases
GPT parsing for PDF data extraction is particularly useful when dealing with unstructured or semi-structured textual content within PDF documents. The flexibility of GPT parsing allows it to adapt to various document layouts and formats, making it suitable for extracting diverse types of information, such as paragraphs, lists, and tables.
Advantages
GPT parsing is easy to use. One can extract data by simply writing prompts in natural language. Furthermore, GPT parsing has the ability to handle a wide range of document layouts and formats. GPT models are trained on multilingual text data, allowing them to extract information from PDFs written in different languages.
Disadvantages
While GPT models excel at understanding natural language and contextual information, they may struggle with extracting structured data or tabular information from PDF documents. Furthermore, GPT parsing might struggle to extract large amounts of data. For instance, many paragraphs of text.
What Methods Do We Use at Parsio to Parse PDF Documents?
At Parsio, various methods are employed to parse PDF documents efficiently. OCR technology is utilized to convert scanned PDFs into machine-readable text, enabling the extraction of information from images or scanned documents. Parsio provides a template-based parser, pre-trained AI models, and GPT-powered parser.