How to Extract Tables from PDFs Automatically: OCR, AI & LLM Methods Compared
Learn how to extract tables from PDFs automatically using OCR, AI parsers, and LLMs. Compare methods and find the best one for your use case.


Introduction
Extracting tables from PDFs is one of the hardest challenges in document processing. Tables come in all shapes and formats. Some are simple and well-structured. Others are scanned images with complex layouts.
The good news is that you don’t need to extract tables manually. Today, tools like OCR, AI parsers, and large language models (LLMs) can automate the process.
In this article, we’ll explain why table extraction is tricky and compare three effective methods: Zonal OCR, AI parsers, and LLM-based table extraction.
Why Table Extraction Is Hard
PDFs are not designed for data extraction. A table might look clean to a human, but to a computer, it’s just text floating on a page. Common challenges include:
- Tables that are actually images (scanned PDFs)
- Multi-line rows or merged cells
- Missing borders or inconsistent spacing
- No defined column headers
These problems make it hard to convert tables into structured data like CSV or JSON.
Typical examples include:
- Invoices with line items
- Purchase orders with product tables
- Bank statements with transaction rows
Let’s look at how to handle these using three main approaches.
Method 1: OCR + Zonal Table Extraction
How it works
Zonal OCR uses Optical Character Recognition to read text from scanned images or PDFs. Then it extracts data from predefined zones. You define zones based on coordinates or grid positions.
Pros
- Works for scanned documents
- Reliable if layout is fixed
- Doesn’t rely on AI interpretation
Cons
- Doesn’t handle layout changes well
- Manual setup needed for each layout
- Errors in OCR can distort table structure
Best for
- Receipts, delivery slips, printed purchase orders
Learn more in our guide to Zonal OCR and how to convert scanned PDFs to text.
Method 2: AI-Powered Table Detection (Pre-Trained Models)
Data extraction platform example: Parsio.
How it works
AI parsers are trained on thousands of real-world documents like invoices and bank statements. These models recognize table structures, row boundaries, and fields like "item," "price," and "quantity."
No need to define zones—just upload a document and let the model do the work.
Pros
- Easy to use, no manual rules
- Handles layout variations
- Fast and accurate for supported document types
Cons
- Only works for document types it was trained on
- Limited customization for niche documents
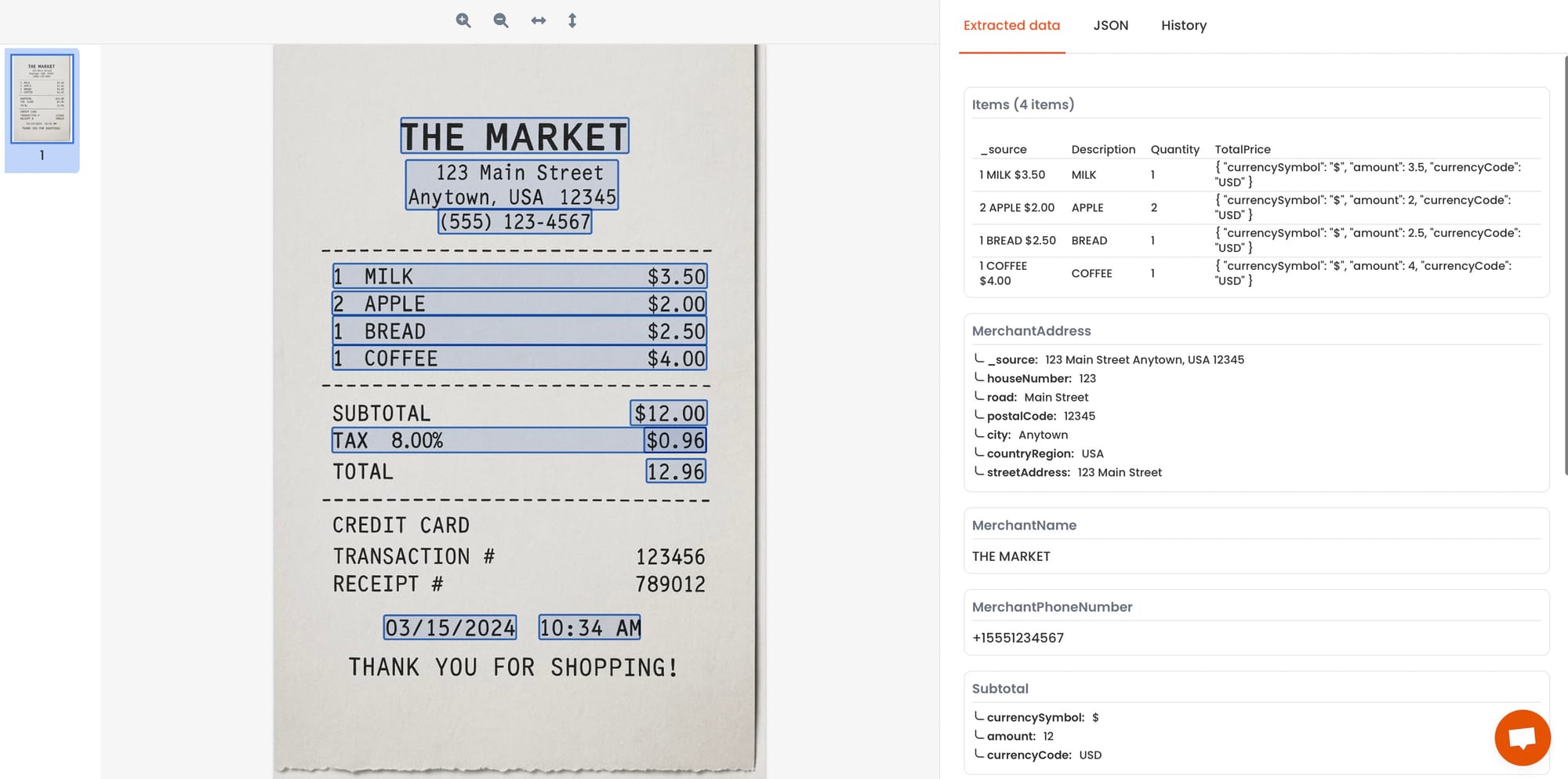
Best for
- Invoices from multiple vendors
- Bank statements and expense reports
Read more: How to convert PDFs to JSON with AI and Top bank statement parsers in 2025.
Method 3: LLM-Powered Table Parsing
Data extraction platform example: Airparser.
How it works
Large Language Models (LLMs) like GPT or Claude can read and understand any text content, including tables. You provide a schema (for example: item, quantity, price), and the model fills in the rows based on context.
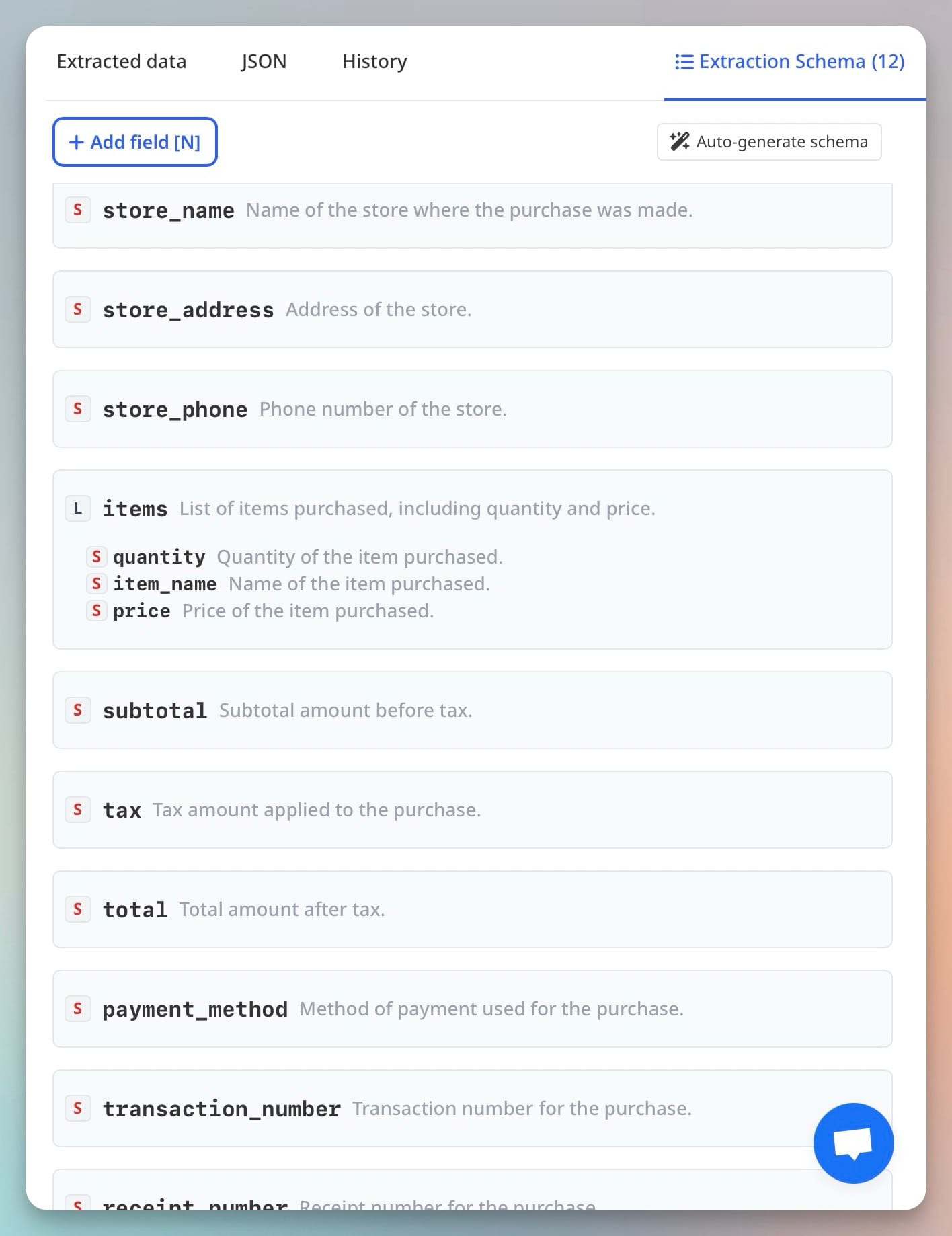
This works even when the document is messy or lacks a clear structure.
Pros
- Very flexible
- Works on almost any document
- No templates or training needed
Cons
- May return incorrect or made-up values (hallucinations)
- Slower than other methods
- Less predictable at scale
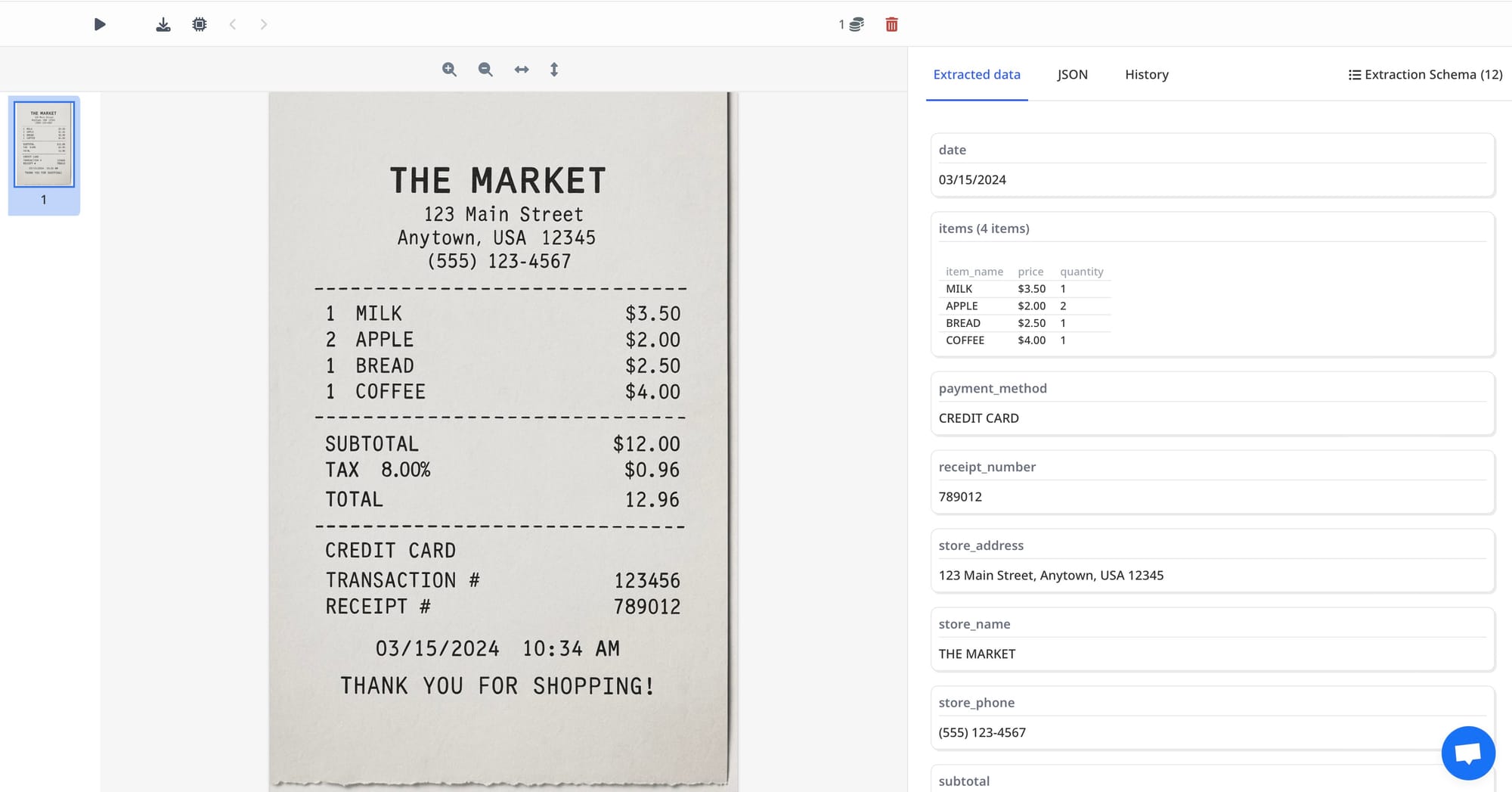
Best for
- Contracts with embedded pricing tables
- Custom reports and niche formats
Related articles:
Choosing the Right Method
Here’s a quick way to choose the best table extraction method:
| Use Case | Best Method |
|---|---|
| Scanned receipt or form | Zonal OCR or AI parser |
| Multi-vendor invoice | AI Parser |
| Contract with price table | LLM Parser |
| Bank statement (standard) | AI Parser |
| Custom financial report | LLM Parser |
Use OCR when dealing with scanned files. Use AI parsers when layout varies but the document type is common. Use LLMs when flexibility is key.
In some cases, a hybrid approach works best. For example, use AI for basic fields and LLMs to capture edge-case table rows.
Conclusion
Table extraction doesn’t need to be painful. Whether you’re dealing with invoices, statements, or custom documents, there’s a solution that fits.
- Zonal OCR is great for scanned, consistent layouts
- AI models are perfect for common business documents
- LLMs handle everything else
Parsio supports all these methods, so you can pick the one that fits your needs.
Try Parsio for free and extract tables from your PDFs in minutes.
