PDF Data Extraction and OCR: The Ultimate Guide


The Portable Document Format (PDF) has been indispensable for professional and every-day life ever since its creation in 1993. Secure, accessible to a wide audience and extremely convenient in its portability, PDF files are used pretty much in all spheres of people’s life containing great volumes of important information to be processed. This is an especially hot topic for enterprises which receive and generate countless PDFs every day: invoices, bank statements, receipts, business cards and so on…
What are the situations when a PDF parser comes out pretty handy?
- Companies issuing invoices automatically need to store all the customers’ information and past transactions in one place. With the help of a PDF scraper, the data from invoices can be downloaded automatically into a database and kept there for the accounting purposes. Receipts, tracking purchase orders, bills and shipping notes can be processed after scanning, and the accounting software can thus be fed with the extracted data.
- Headhunting firms need a PDF parser to extract and structure data from the candidates’ CVs.
- Valuable information such as name, address, phone number can be extracted from ID cards and passports with the help of a PDF parsing tool.
- Businesses processing tables, repetitive data and line items in PDF files will be able to do it easily with the help of a PDF parser.
The data contained in these documents should, in most of the cases, be extracted in order to get processed or exported elsewhere. Copying the lines of the PDF documents one-by-one is a routine and error-prone work requiring additional human workforce and a lot of time.
What challenges do companies face if they need their data to be extracted from PDF files?
Unlike other-type documents like CSV, DOC or XLS where data extraction and editing is pretty easy and plain (you just copy and paste the lines you need), extracting data from PDFs can be quite challenging. You can’t just edit the lines you need to extract, and copying-pasting doesn’t preserve the original structure and format – especially when talking of tables. As a conclusion, the data contained in a PDF file is pretty much inoperable apart from having a look at it.
So what are the solutions if you need to extract data from PDFs in bulk for professional purposes? We are going to revise them all - from the ordinary and manual ones to the most recent and automated ones.
PDF Parser Tools: Definition and Classification
Before talking of ways to extract data from PDFs, it's important to define what a PDF parser is. It’s a software that extracts data automatically from PDFs. The parsed data can then be exported to an accounting system, CRM, marketing platform, Google Sheets, Database using an automated workflow.
And why is a PDF parser (sometimes also called PDF scraper) so helpful?
First of all, it allows you to save a great amount of time that you’d otherwise put into manual data extraction/entry and - which is equally important lets you avoid human-factor errors.
- Apart from that, with the help of a parser tool you no longer need to manually enter your data into your CRM system or any other database of your choice: all your data will be streamlined automatically right where you need.
- The excellence of your extracted data quality will be unbeatable since the automated data entry will always be a lot more accurate than the manual one.
- Finally, the parsing tool doesn’t need to take days off to rest - it will keep processing your PDFs even when your business is on holiday.
With the help of a parser tool, the data will find its way from your PDF to its place of storage automatically and in no time.
We can distinguish the 5 most popular ways to extract data from a PDF file:
- Manually.
- Using an online OCR tool.
- Writing a custom Python parser.
- Using a zonal OCR parser tool.
- Using an AI-powered PDF parser.
In this article we are going to cover each of them in detail.
1. Extracting Data From PDF: The Manual Way
First of all, you can always just copy and paste the data manually - it can turn out to be rather convenient if you deal with simple PDF documents and if there aren't many of them. It goes without saying that scanned PDF documents create a serious limitation - they don’t allow you to operate the data contained in such a document.
You can also outsource data extraction to dedicated employees or opt for outsource workforce – it won’t cost you a lot of money immediately and will be relatively quick. There are numerous online platforms offering this type of service. It’s a good solution when dealing with a larger number of documents; however, even being cheap “on the spot”, it can become rather expensive in the long run, as well as error-prone, just like any other manual work. The last thing is that many companies often have to deal with highly confidential documents so it’s not quite appropriate to entrust their processing to third parties.
2. Using an Online OCR Tool
There is also a solution of using OCR online tools. There exist nowadays quite a few online softwares allowing you to extract data from your PDFs online like Smallpdf and Cometdocs. They convert your PDFs into a text which allows you to then just copy this text and paste it where you need. They become more and more specialized and designed for different kinds of uses. The inconvenience of this solution is that it’s still not an automated kind of work, your layout will not be preserved and in the end you might receive quite a lot of recognition errors. Last but not least is that some tools should be downloaded directly to your PC (for example, Tabula).

In a nutshell, all of these "manual" approaches are viable but not automated. Not only do they require a lot of manual work but also may turn out to be rather expensive, error-prone and time-consuming. All of these solutions have more or less the same cons. Either you have to invest your own time and effort to perform manual data entry, or have to invest money on a regular basis (which makes it quite a big sum in the long run), or - again - waste time on correcting the final result. On top of it, security is not guaranteed with online PDF converters so globally it’s difficult to say that all these simple approaches are the best.
3. Extracting Data With Python
Python is a powerful programming language that can be used to create a wide range of applications. It is often chosen as the primary language for data extraction and data manipulation algorithms.
You can write your own PDF parser for any custom needs using various libraries for data extraction and parsing, such as pypdf and PDFMiner (not actively maintained anymore).
These libraries extract data from text-based PDF files (generally to a JSON or plain text format), and Python also has libraries to digitize scanned PDFs using optical character recognition (OCR). Tesseract OCR is one of the most popular libraries utilized in this area.
The parsed unstructured data can then be further processed to extract valuable data such as invoice IDs, customer information, and table data. To do this, Python offers various tools such as regular expressions, natural language processing, and machine learning algorithms.
The main advantage of a custom PDF parser is that you can build any custom application that best fits your business needs. However, it is clear that writing a custom parser from scratch is a complex process that requires a significant initial investment, a technical team, and support.
4. Zonal OCR to Extract Data From PDFs
A more complex but more accurate and, which is equally important, a no-coding solution to extract data from your PDFs is Zonal OCR (Optical Character Recognition). This approach is available with different tools like LogicalDOC or Chronoscan and consists in reading specific areas or “zones” of a document (PDF, JPG, PNG or TIFF file) with the help of a special OCR template. Zonal OCR extracts only the essential data fields from a scanned document making it possible to store the extracted values. Zonal OCR is widely used when it comes to, for example, automated invoice processing. It saves you hours of monotonous repetitive work: all you need to do is to just set up a template.
So what is Zonal OCR and how does it work?
Zonal OCR is a type of optical character recognition that allows the software to read specific areas or “zones” of a PDF document. Once you’ve uploaded a sample file, you need to draw rectangles associated with titles or names from your documents: they will be the zones the OCR parser will extract the text from.
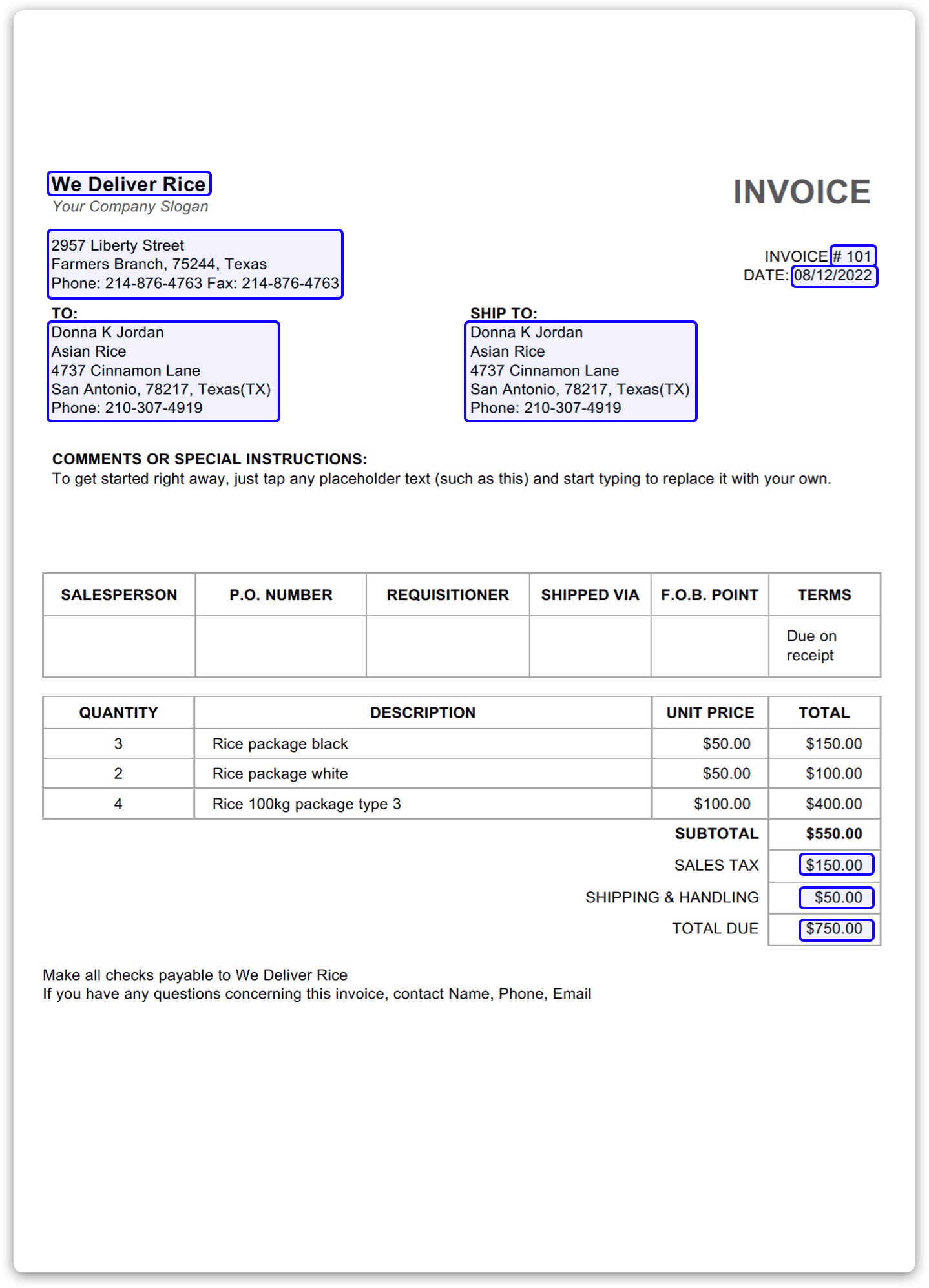
Overall, it’s a good and convenient approach to work on very simple PDF files with the same layout. However, just like the approaches listed above, it has a number of limitations:
- First of all, it takes time to draw zones thus creating the template.
- There is a certain difficulty when it comes to parsing tables: you need to draw columns and rows but all the tables are different in terms of the height, the row number or the column width.
- On a sample file, a specific zone is dedicated to the text you need to extract but this emplacement might differ in the other files you will send later: this zone might move horizontally or vertically (it mostly depends on the text length before this specific zone).
- Finally, the zone’s width and height can often be dynamic (it depends on the text’s length inside the zone), so our zone’s size in the template might not match the text in any other PDF file you need to process.
5. Machine Learning: The New Automated Way to Parse Your PDF Files
One of the most up-to-date and efficient ways to extract your data from PDF files is by means of Machine Learning. You must have already heard this term many times but we bet you’re still not quite sure what it means. Artificial Intelligence, Machine Learning, Deep Learning… What are they and how do they fit together? Let’s take a dive and find out!
Even those who are far from the world of data science have inevitably heard about Artificial Intelligence (AI), Machine Learning and Deep Learning that become more and more part of our daily life. You might think these terms are interchangeable and mean more or less the same technologies-driven future but if we take some time to reflect, we’ll see that there is so much more to the meaning of each of them.
Generally speaking, deep learning is a variety of machine learning, and machine learning is a type of artificial intelligence. In other words, AI is broader than machine learning and deep learning so you can present them in the form of 3 overlapping circles. This makes DL part of AI but AI itself is not DL.
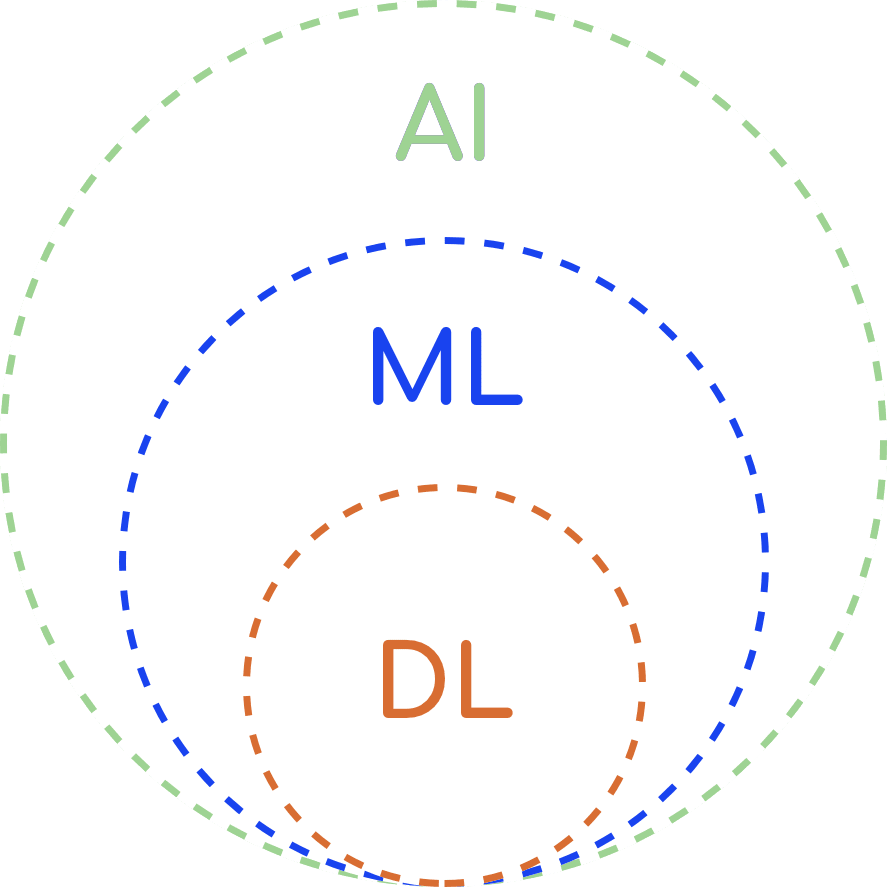
Artificial intelligence can be defined as the capability of a device to perform functions that are normally associated with human intelligence, such as reasoning, learning and self-improvement. As for Machine Learning, the Oxford dictionary defines it as “the use and development of computer systems that are able to learn and adapt without following explicit instructions, by using algorithms and statistical models to analyze and draw inferences from patterns in data”. Finally, deep learning is a type of machine learning that uses artificial neural networks to imitate the learning process of the human brain, and machine learning is the type of AI with a capability of automatic adaptation with minimum human involvement.
Back to our topic, how can all of them be helpful when it comes to extracting data from PDFs?
The most recent and the most advanced solution for parsing scanned documents is PDF parsing with the help of machine learning. This AI parsing solution reduces manual effort to minimum. Automated data extraction AI tools use machine learning to provide pre-trained extracting models that can deal with many specific types of documents (invoices, business cards, passports and ID cards, W-2 forms, contracts, etc). Apart from using pre-trained extraction models, you can also train your own custom AI models, with just a few steps to follow:
- Collect a few documents serving as a training set (usually, 3-10 documents is enough to train a ML-based model).
- Highlight the data to extract from the demo set.
- Verify your results and correct the parsing errors. The ML model will learn every time you upload a new document and correct the parsed results.
Once these stages are completed, you can run the software on real documents and handle your processed data. Even the handwritten text can be easily processed with the help of an AI engine. From now on, the data extraction will only take you a couple of seconds whatever document you need to process: you just upload it - and wow, all the data is extracted according to the document type, accurately and in no time! With the help of such a tool we can create a model for every type of document so the extracted “amount”, “address”, “name” and other lines will perfectly correspond to the ones in the document, without any effort from your side.
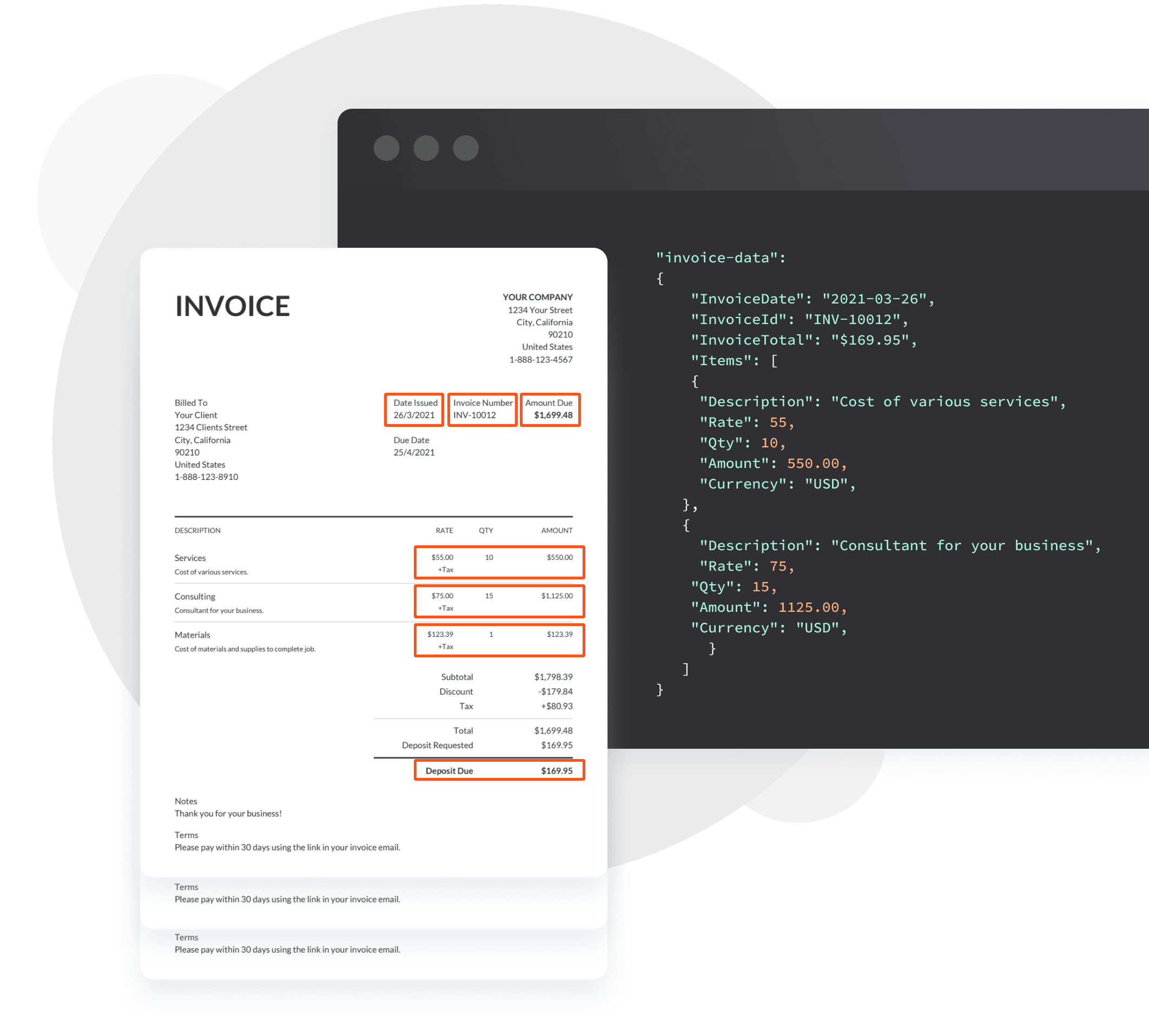
More advanced solutions like this one also allow you to automatically import your PDF files, either by means of auto-forwarding in email attachments or through API.
Automating Data Extraction With Parsio
Machine Learning parsers seem to be the best PDF processing solution so far. Could there exist anything even better than that?
The answer is yes, and it’s a parser tool that unites all the possibilities and meets all the needs: from email parsing to PDF processing with the help of Artificial Intelligence and Machine Learning. Meet Parsio!
Parsio – the ultimate way to extract data from PDFs
Parsio is a tool that presents in itself a unique all-in-one tool in terms of email parsing and data extraction. This no-code software combines generic template-based email parsing and machine learning, which makes it an out-of-the-box solution capable of automating your workflow from all the sides.
With Parsio, you can parse emails, PDFs and files including images, scanned text, tables, CSVs and many other document types. With the new machine learning function, there are supported pre-trained AI models available that will parse in a wink of an eye the most common types of documents:
- Invoices
- Receipts
- Business cards
- Identity documents: ID cards, passports, driving licenses etc.
- W-2 forms (US)
- General documents and forms including handwritten language
So how does it work?
1. First, you need to create a mailbox, choose "I will parse PDFs and images" and select a pre-built model.
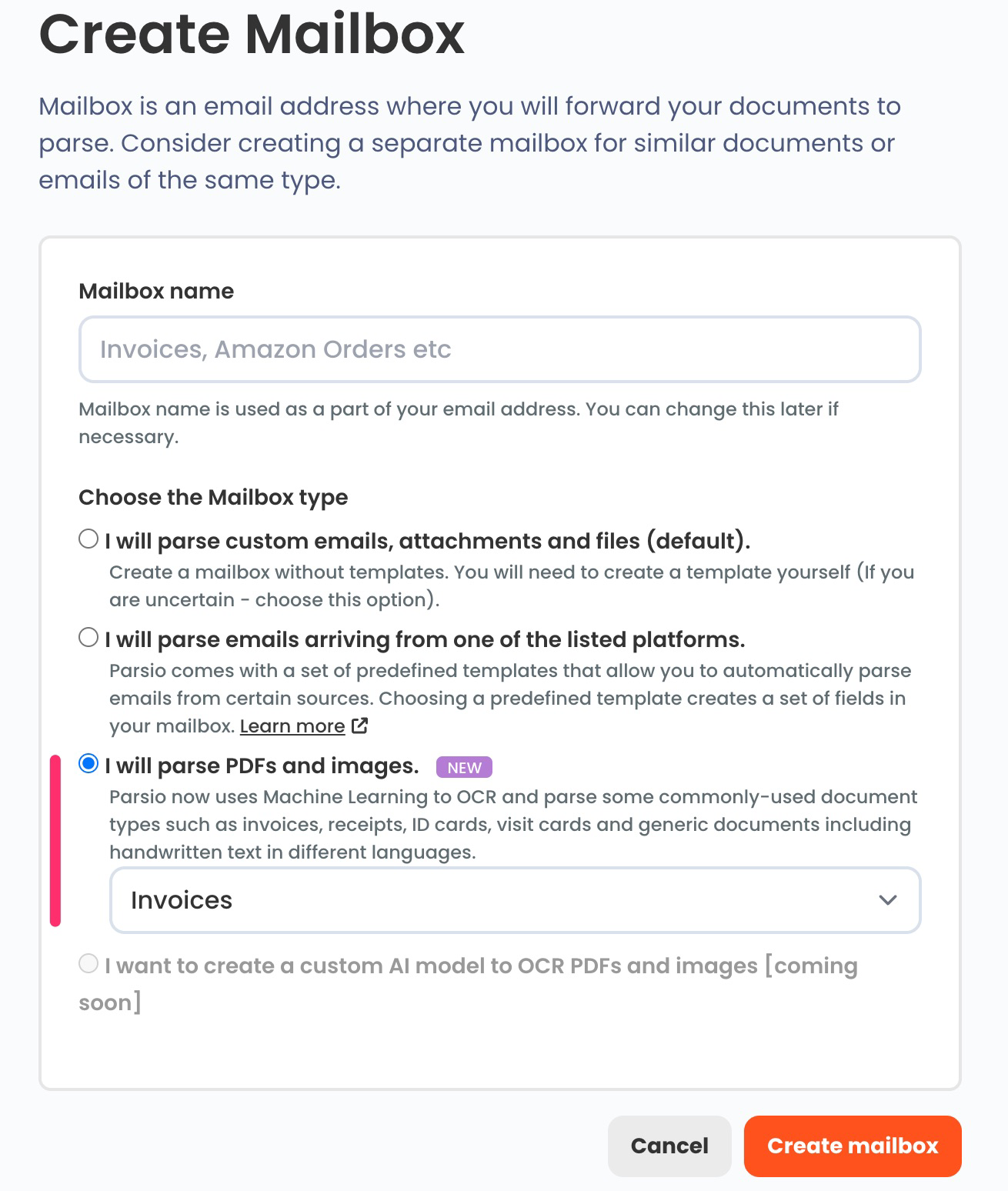
2. Import your first PDF file either by sending as an email attachment or by uploading it manually or through API.
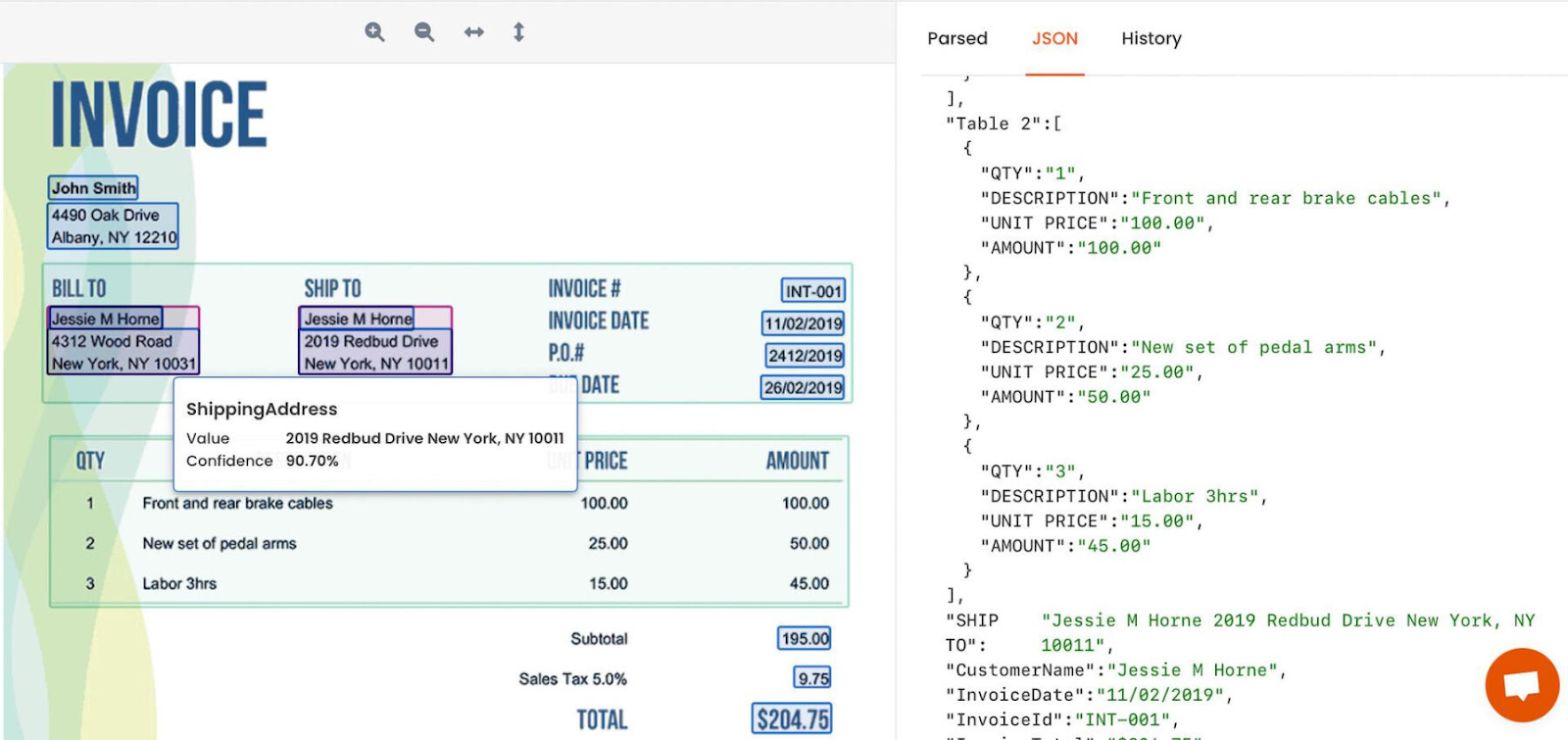
3. It’s all set up! Now you can export the parsed data into Google Sheets or to any other place of your choice (a CRM database, Slack or Trello) with the help of automation platforms or webhooks.
Going Further with Parsio: automate your data export and the data entry process
Parsio doesn’t only allow you to extract data automatically from all types of emails, PDF files and attachments but also makes it possible to export the data to any place of your choice. Here are just a few examples of how you can manage your data with the help of Parsio:
- You can export your data automatically to Google Sheets with a built-in integration.
- With the help of automation platforms like Zapier, Make, Integrately and KonnectzIT you can create connections/scenarios to automate your workflows: notify your team about new leads, subscribe clients to newsletters, upload your attachments automatically to cloud storage and many more.
- Your data can be automatically exported into Excel from PDF.
- Your attachments can be saved automatically to OneDrive, Dropbox and Google Drive.
- Finally, you can parse automated emails from many different platforms including Airbnb, Haro, Etsy, Booking.com, Zillow, Eventbrite and many others.
As you see, Parsio goes far beyond simple email parsing and presents an out-of-the-box solution that can facilitate your routine so much by means of automating your workflow thus boosting your business and sales.
Check out our articles on how it all started to get to know Parsio better and follow our Twitter for awesome tips and novelties!
